- No Longer a Nincompoop
- Posts
- Meta Goes All In
Meta Goes All In
Nofil Khan
July 27, 2024
Welcome to the No Longer a Nincompoop with Nofil newsletter.
Here’s the tea 🍵
Elon Musk’s new compute cluster 🖥️
Meta releases Llama 3.1 🤖
The EU has a problem 🫣
Elon musk announced xAI has put together the most powerful compute cluster on the planet. The cluster contains 100K, NVIDIA H100 GPUs. Yes, 100K.
What’s so impressive about this is that they managed to put it together in just 19 days. The cluster isn’t fully operational just yet, however, by the end of the year, xAI will be training Grok3 on 100K GPUs.
New King
Meta has released three new variants of their Llama3.1 model - 8B, 70B and 405B. Each model is leading across models their size.
The 405B model is the best open source model on the planet. In fact, it’s very close to being the best AI model on the planet, irrespective of being open source or not.
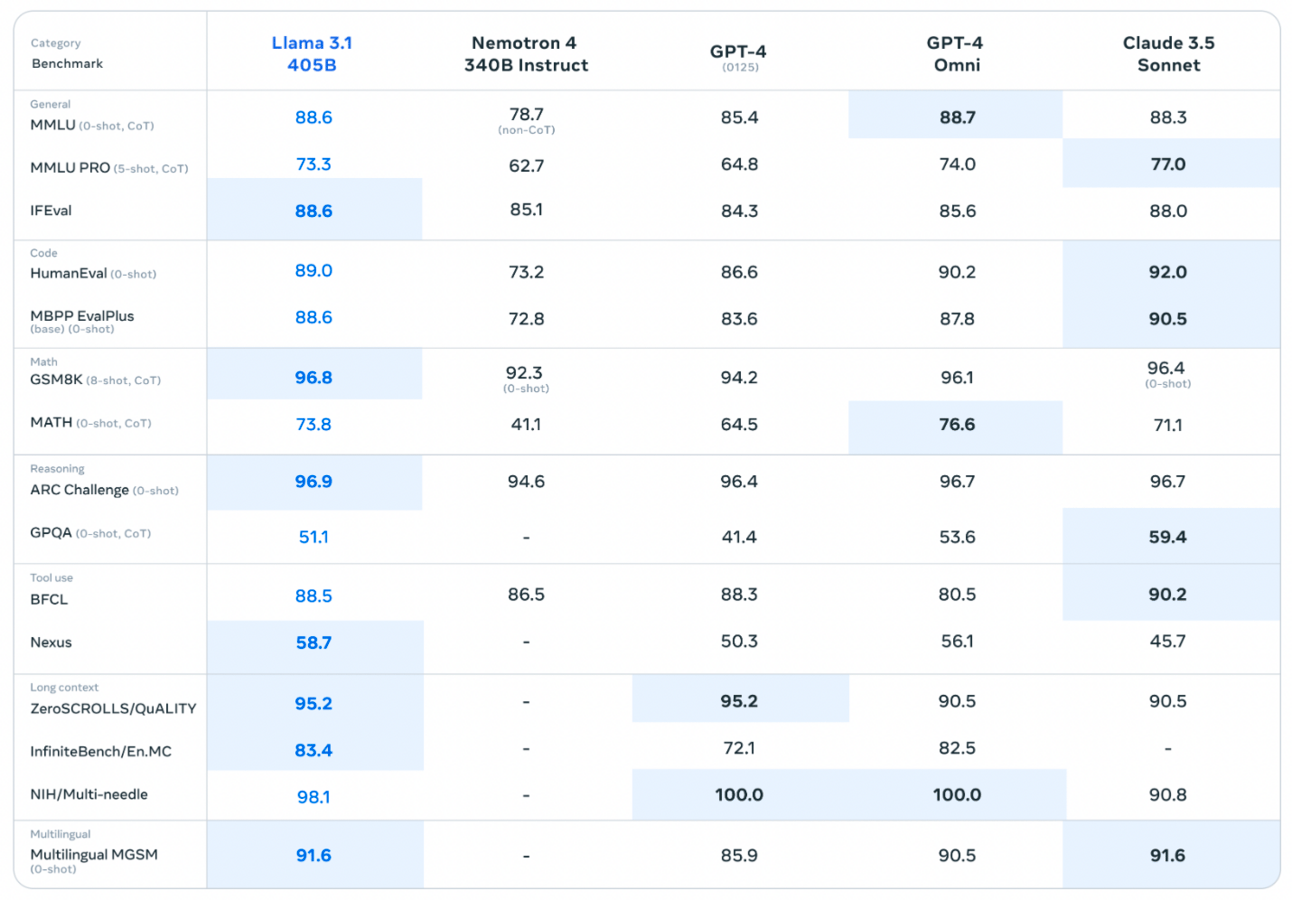
It’s not just a matter of benchmarks either. As you know, I don’t really believe in those. Human preference is a lot more important.
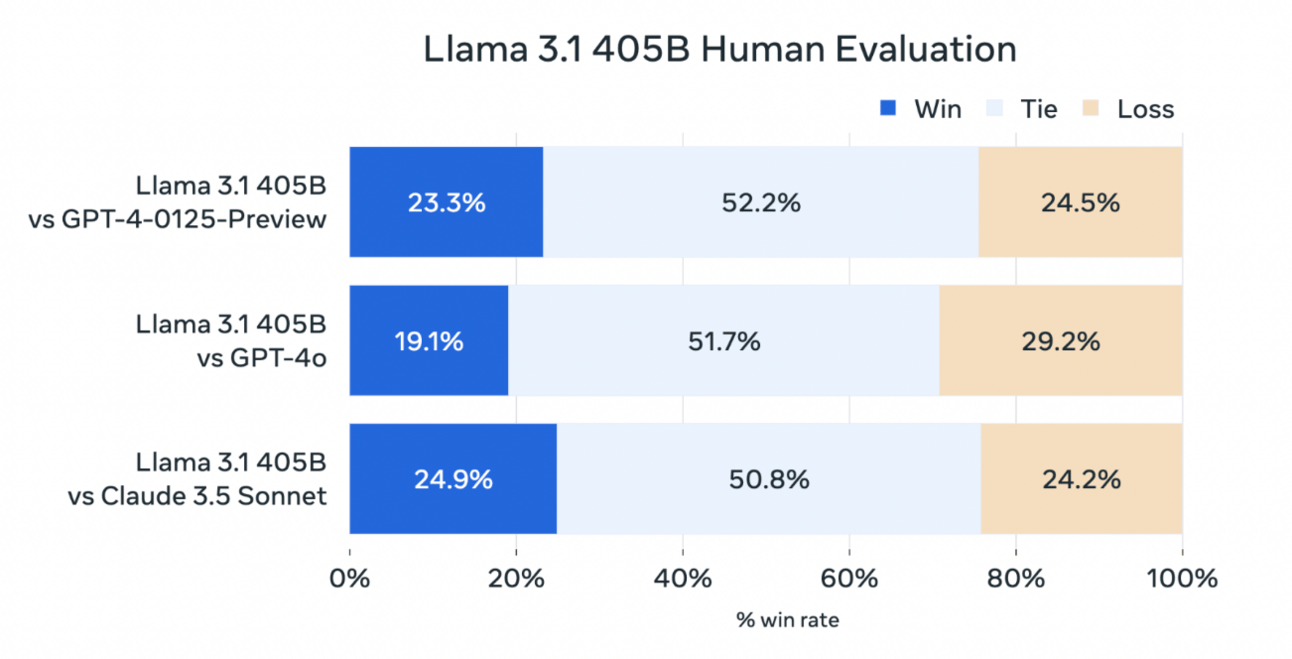
Technicals
The model has been trained on 15.6 Trillion tokens and Meta used over 16,000 H100 GPUs to train it. With a reported 40 Million GPU hours to train the model and at an average of ~$4/hour, the cost of training the model is a mere $160M.
For something as innovative and important as one of the leading AI models on the planet, the costs are surprisingly not that high.
Obviously, this is napkin math with a lot of other factors excluded, but generally speaking, the overall cost would still be less than a single Hollywood blockbuster.
What’s even more staggering is when you compare it to the compute clusters being built right now.
If we can get a state of the art model with 16K H100 GPUs, what can we build with 100K GPUs?
The models of tomorrow are going to be built with exponentially more power.
This is a future we must prepare for.
Meta themselves, like many other AI labs, have clearly stated things simply aren’t slowing down, and there is no evidence to suggest otherwise.

It is also apparent thanks to their technical paper, that building a GPT-4 class model isn’t something crazy. OpenAI isn’t sitting on some alien technology. They had a head start in the AI race, but, the speed at which others have caught up to them suggests it’s simply a matter of using current techniques well.
The fact that Meta hard pivoted to AI just over a year ago and now have a model publicly better than OpenAI’s is a testament to this.
Where to use it
There’s a problem.
You’ll have to pay different amounts to use the model depending on the provider. This is fine of course, it’s always like this.
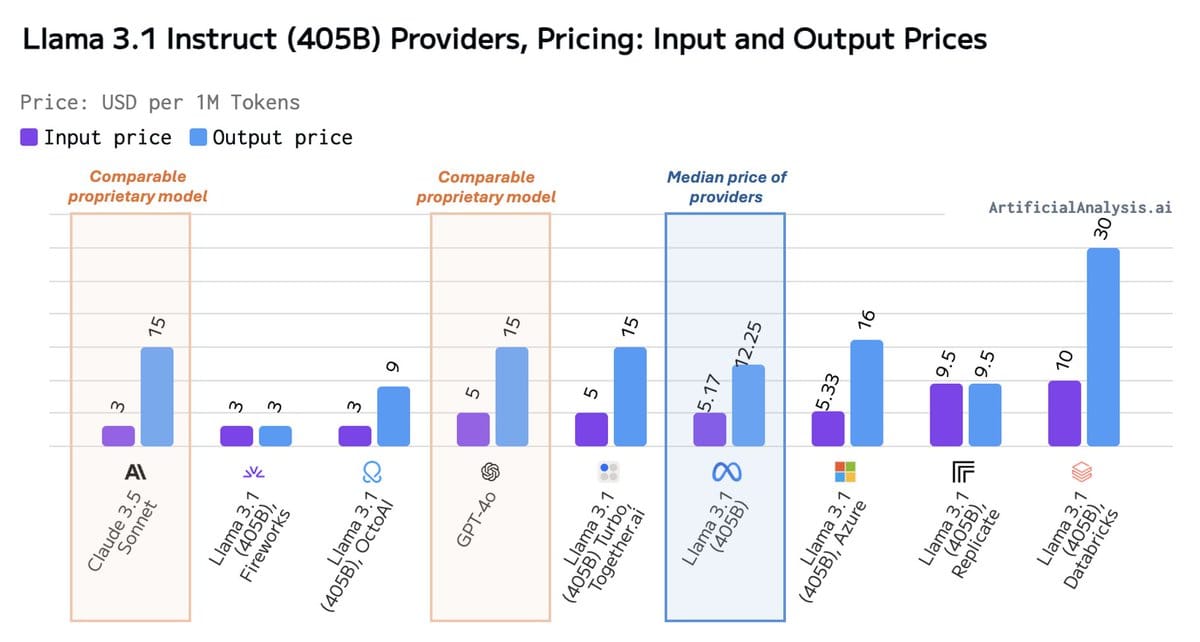
However, this time around, there is also a discrepancy in performance based on who you use it with.
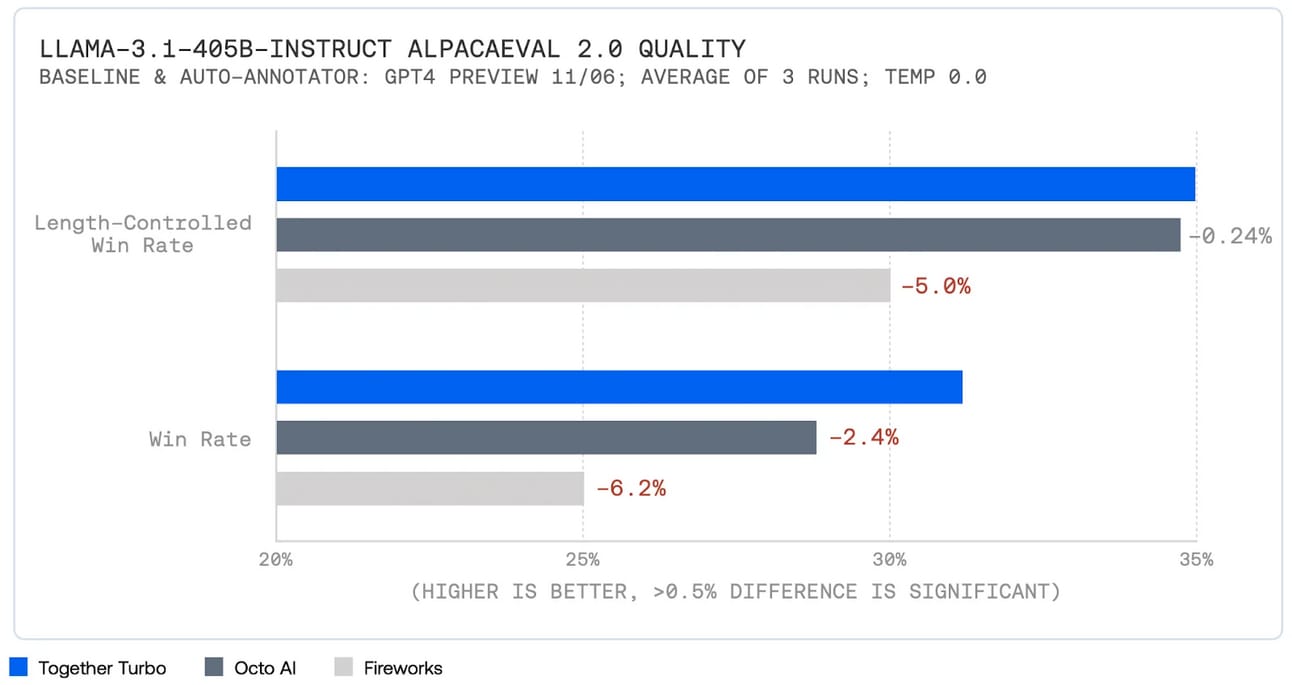
Yes, depending on who your provider is, you’ll have a different experience working with the model. This is due to the quantisation of the model and what techniques providers use to make it easier to host and faster to respond.
Third party services suggest otherwise, but from personal experience and reading about it online, it definitely seems like it feels different across providers.
These are the current providers and their costs.
Provider | Input Price | Output Price | Output Speed (t/s) |
|---|---|---|---|
Lepton AI | 2.8 | 2.8 | 32 |
Fireworks | 3 | 3 | 29 |
OctoAI | 3 | 9 | 25 |
Together AI | 5 | 5 | 69 |
Azure | 5.33 | 16 | n/a |
DeepInfra | 7 | 14 | 11 |
Replicate | 9.5 | 9.5 | 28 |
Databricks | 10 | 30 | 23 |
Performance across providers is not something that is currently being measured or compared as far as I’ve seen. I may try and do this if I have the time.
I was incredibly curious as to how Lepton AI is able to charge so little to run a model so big. These companies are losing tonnes running these models. I thought I could build something on top of their API so checked their website and found this little nugget of info.
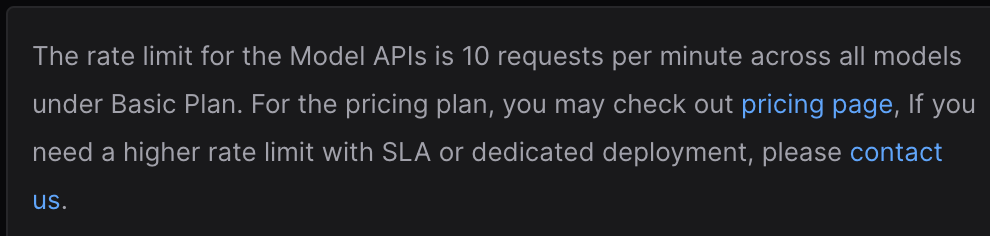
Can’t build a product restricted to 10 requests a minute 🤷. Although, I do think that’s feasible for personal use.
You can run this behemoth model locally with two macbooks. Exolabs is a company allowing people to run their own little AI clusters with the devices they have at home. The code is open source and can be found on Github.
Meta won’t be releasing the follow-up multimodal versions of their new Llama3.1 models in the EU. The EU has a major problem - Meta has called them on their bluff. The company won’t be releasing either the multimodal versions of Llama3.1 or their next iteration of models either.
In fact, even the current Llama3.1 405B, which they’ve already released, goes against the current EU AI regulation.
So has anything happened?
No.
The EU’s desire to regulate AI so early will destroy any capacity for AI innovation in the region. According to the EU, models trained on more than 1025 Flops carry systemic risks.
There is no systemic risk coming from this model.
Any of this fear mongering always reminds me of OpenAI’s views on GPT-2 way back in 2019, or better yet, fears that Saddam was going to build a supercomputer with Playstation 2s.

It’s a shame so many startups and businesses will miss out on using such advanced models that are so much cheaper than closed source alternatives.
Companies will simply leave the EU to use the best AI.
I’m looking to write more and shorter newsletters.
There is so much more information I’d like to share, but in the interest of trying this new format, I’ll end it here.
What do you think?
Shorter or Longer newsletters? |
Like getting this newsletter? Browse all previous newsletters on my website.
Want more? If you want to read longer essays about AI and the constantly shifting lanscape, get access to frameworks, repos, example apps using AI and stay up to date with everything happening across the space — Sign up to the premium newsletter.
If a friend forwarded you this message, sign up here to get it in your inbox.
As always, Thanks for reading ❤️
Written by a human named Nofil
Reply