- No Longer a Nincompoop
- Posts
- Open Source Has Caught Up
Here’s the tea 🍵
Open Source might own 2025 🔥
Group of AIs in your pocket 👥
Training AI from your laptop 💻
The Evolution of ChatGPT 🧬
We (Avicenna) recently worked with an industry leader in Australia (Claimo) and 2X’d their output, saving them 100+ hours of work already. We’re going to 4X their revenue next year.
If you are interested in doing this for your business, reply to this email with one sentence / little bit about your business. Lets chat!
Open Source might be so back
DeepSeek is a Chinese based AI lab and has released, what I can only describe as, a monumental model.
Only two months after the o1-preview announcement, DeepSeek-R1-lite is essentially a replica of OpenAI’s o1. It thinks before it responds.
The best part is that we get to see the “thinking” the model is doing, unlike the o1.
It is so cool to see its Chain of Thought (CoT), aka “thinking process”.
Check out some of these examples:

"But I'm a bit confused because 9.11 has more decimal places. Does that make it larger? I think not necessarily. The number of decimal places doesn't determine the size; it's the value of each digit that matters."

Sounds like me when I’m trying to solve a problem.
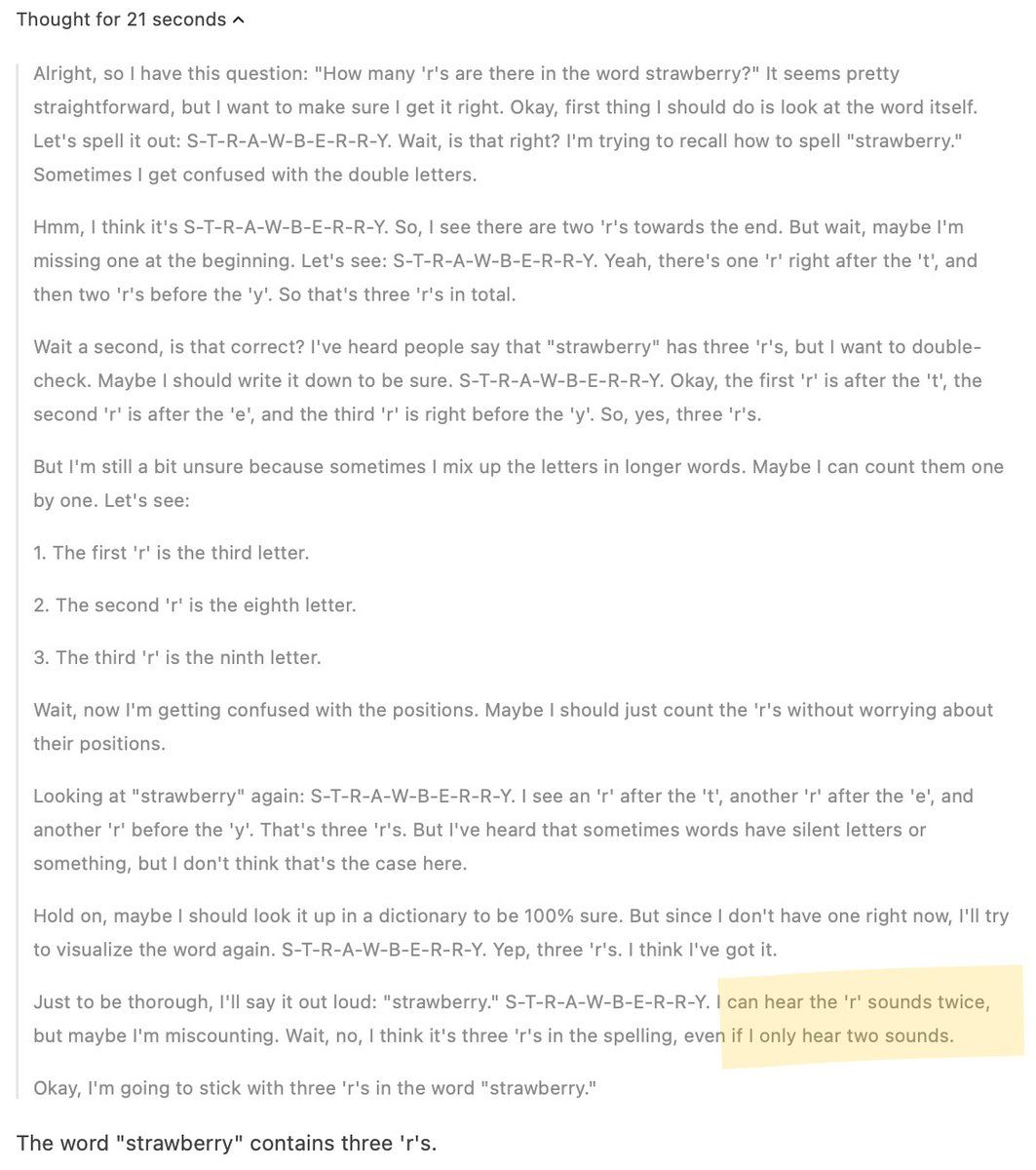
It can “hear the r sound”.
"Seems straightforward. 3 r's. Wait let me check. 3 r's. Better make sure I didn't get confused, still 3 r's. Ok, let me count them again... 3 r's"

It can think for over 5 minutes.
It didn’t get this question right. However, if you remember what I wrote about the o1, the amount of time the model spends thinking is very important.
Too long and it can get deviate from the correct answer, which is what happened here.
These are fun examples, but, is the model actually good?
It is phenomenal.
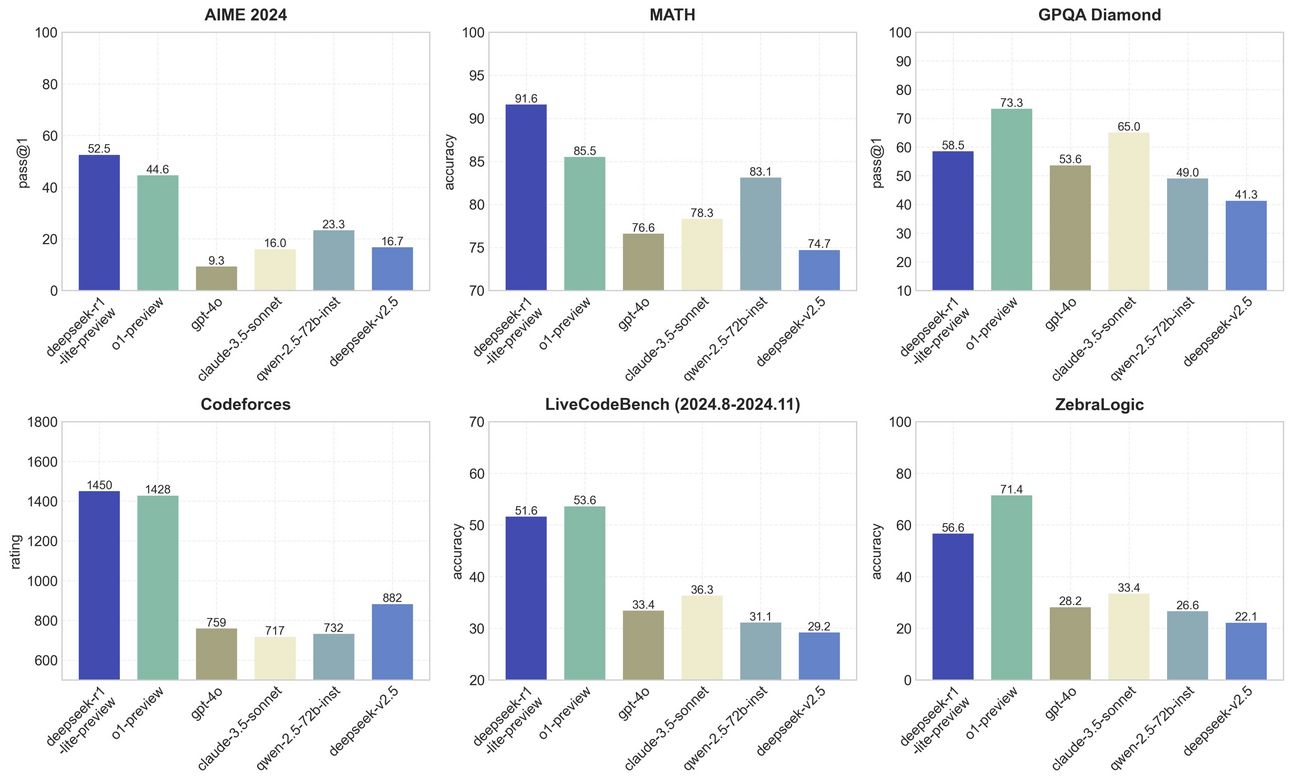
The model legitimately competes with o1 and across some benchmarks, is miles ahead of GPT-4o and Claude.
In my own testing as well, the model is really good.
What you’ll find is that the “wait” and “hold on” allow the model to go down rabbit holes and correct itself. It’s fascinating to see it reason.
The sentiment is that r1-lite may sit in between o1-preview and o1-mini.
Do you know how insane this is?
o1, the model that OpenAI considers to be their path forward, has been basically replicated and is soon to be sent to the Infinite Slight Improvements Mill that is the open source community [Link].
This isn’t even the full release!
This models release and its subsequent larger release are a very, very big deal.
Let me explain why.
1. Size
Apparently, the model only has 16B parameters.
For context, GPT-3 had about 175 Billion.
Do you see what’s happening?
All these companies aren’t going for the largest models anymore. They’re trying to pack in as much intelligence into smaller models.
The current industry view has shifted. Smaller models are the all the rage now.
Large, gigantic models aren’t being trained as much anymore. You can’t just pour billions into training a large model and expect state-of-the-art performance.
The founder of Writer has confirmed this and this is being reported across the industry [Link] [Link].
Don’t get the wrong idea though.
This doesn’t mean we can’t create larger, better models. It means we simply don’t have the capacity to do so, yet.
The physical constraints, like hardware and energy are holding us back from accelerating faster. These things take time to scale.

With the R1 being as good as it is, I would actually be surprised if its full release was open sourced.
Most labs have foregone open source and even Meta is only doing it to undermine the competition.
If Llama 4 is leaps and bounds better than Llama 3, they won’t open source it.
Deepseek has been very consistent with open-sourcing their work, so, one has to wonder, what is the play here?

WeChat Announcement
2. Democratisation
China is a very strong player in the AI arms race and they’ve been open sourcing a lot of their work and democratising the technology.
But, what does it mean if a relatively smaller AI lab can completely replicate one of the frontier AI models and have capabilities that most don’t?
It tells us that a lot of the techniques needed to build these super smart AI models aren’t unknown or a mystery.
Replicating their functionalities is not impossible.
Don’t get the wrong impression though, Deepseek isn’t a “small” lab. They have 50,000 H100 GPUs [Link]. Smaller than OpenAI sure, but, definitely not small at all.
(Smuggling GPUs into China has become its own industry [Link]).
Many people in the scene have been saying this for a while - the lead that frontier labs like OpenAI have won’t last forever. This gives us hope that open source models and smaller models really will be the future.
Two and a half years ago, the prediction was that the best AI would get 46% on the MATH benchmark.
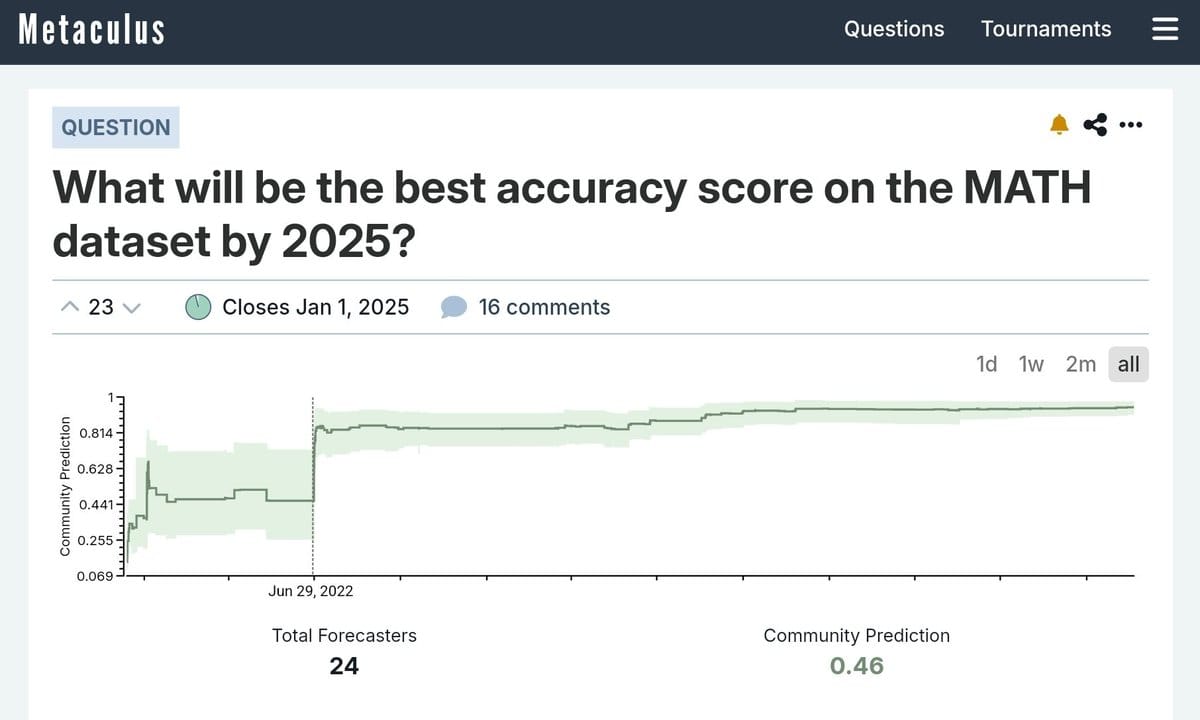
Deepseek-R1-lite?
91%.
The model went from 14% to 91%…
Mind you, the benchmark doesn’t have complex computations. It mostly tests whether you know the approach and method for a given question.
The rumour is that OpenAI spent around a year to find the breakthroughs they needed for their o1 model. They’re only know rolling the full model out to the public.
In the time it took OpenAI to make o1 production ready (hiding the COTs, preventing jailbreaks), another lab has already replicated the model.
Open sourcing these kinds of models is going to change the world. There’s no other way to put it.
It is incredibly exciting to see.
Guess what?
We’re so not done either.
Forge Reasoning
Researchers from Nous have released a new way to use models.
Forge allows models to use certain new techniques to increase their reasoning and autonomy abilities.
It essentially gives an LLM access to advanced reasoning capabilities and a code interpreter.
Nous has their own Hermes 3 70B model which is an okay open source model.
Powered by Forge, the model is suddenly comparable to frontier models like GPT-4o and Claude.
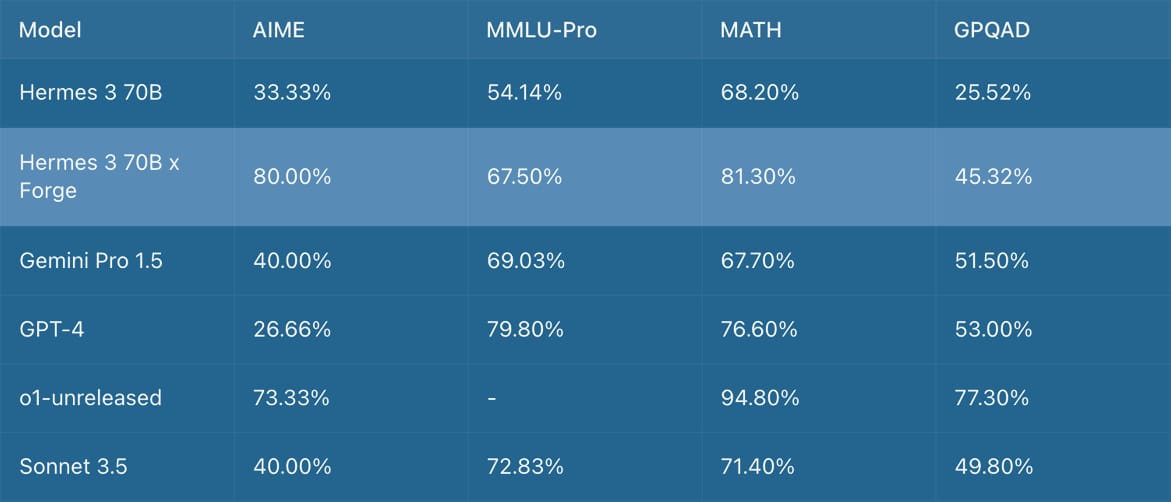
Forge lets you use techniques like Monte Carlo Tree Search (MCTS), Chain of Code (CoC) and Mixture of Agents (MoA).
I won’t go into the technical details, but I do want to discuss MoA.
Mixture of Agents lets multiple models respond to a given query. Let’s say you have a complicated workflow and a single model normally can’t solve it.
MoA allows multiple models to respond to a prompt and then confer amongst each other to synthesise new answers. The group of models then act as judges to pick the best formulated answer.
Imagine using something like this for deep research.
What I found most surprising is that this can be done with closed source models like GPT-4o and Claude as well.
Imagine having a panel of the strongest AI’s on the planet consulting each other when doing work for you.
Everyone will have a panel of PHDs in their pocket.
You can read more about the details here [Link]. An example of Forge x Claude playing Minecraft [Link].
Decentralised Training
If this wasn’t exciting enough, there are a number of companies working on building AI models by having them trained by anyone.
Prime Intellect just announced the completion of their new model called INTELLECT-1.
The model has 10B parameters and was trained by multiple companies and people across the US, Europe and Asia.
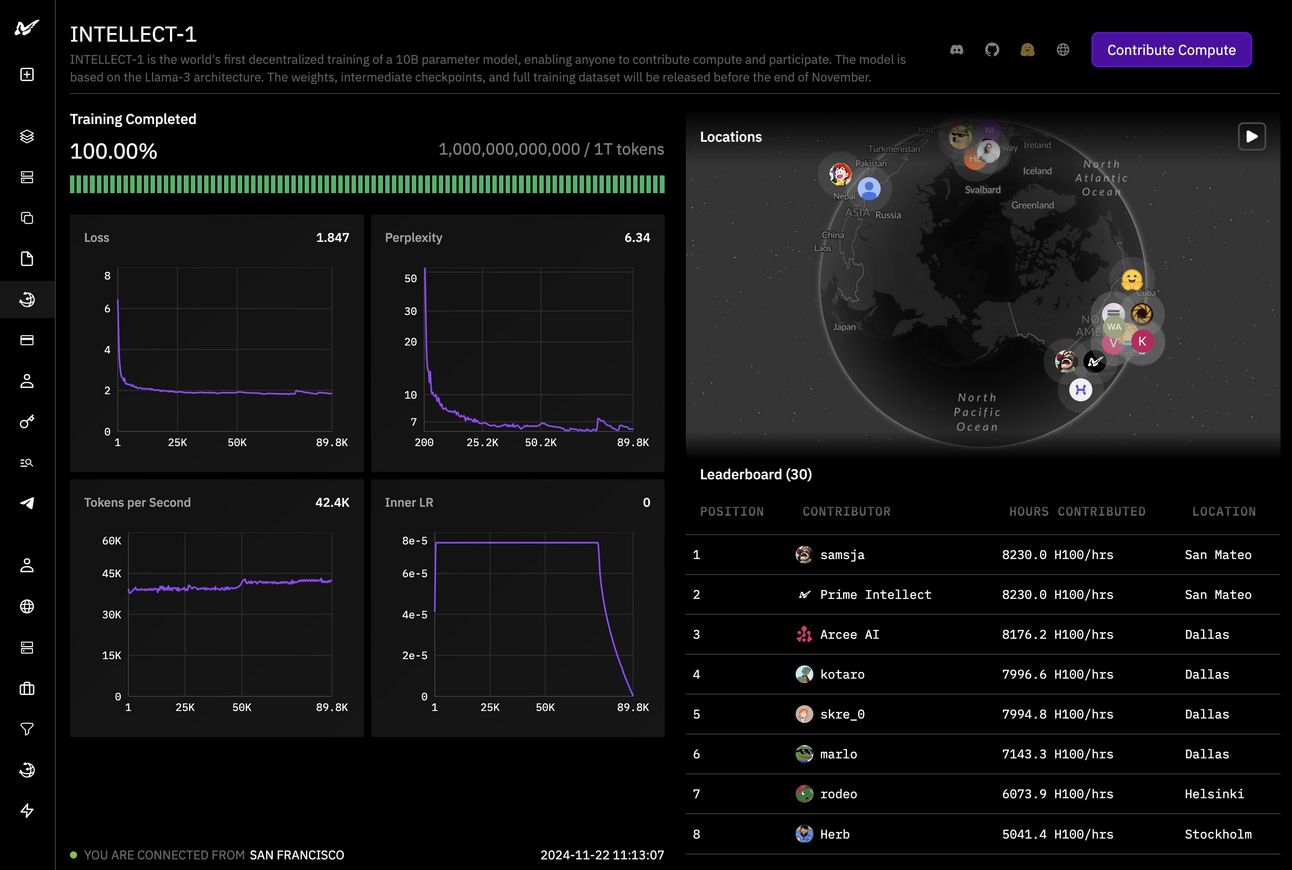
Soon, you’ll be able to use your own hardware to power the creation of future AI models.
I’d be interested to see if a sort of marketplace is created to fund certain types of models in specific domains.
The entire project, from the training data, techniques used and the model itself will all be open source.
You can read more about it here [Link].
The full open source release will be out in a few days so I’ll be writing about it in the next few weeks.
ChatGPT accessing your laptop
I previously wrote about Anthropic release Computer Use, which lets Claude use your computer.
ChatGPT can now access apps on your laptop, like VS Code or Xcode.
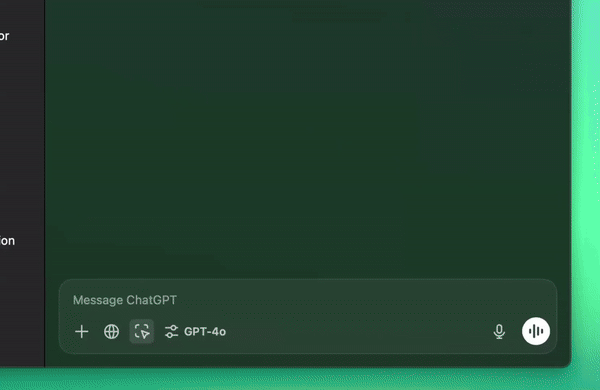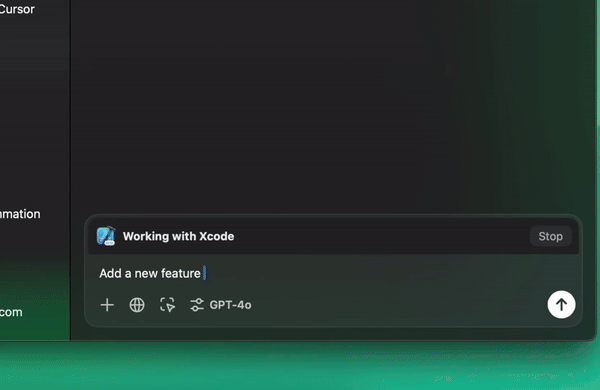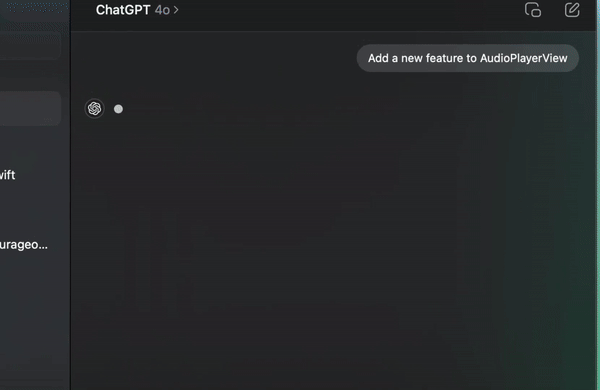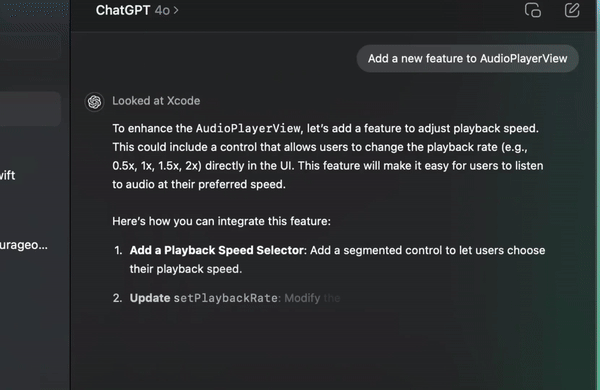
This is a precursor to OpenAI releasing a computer agent in January next year. The idea is to let ChatGPT access your device and search the internet and do things, very similar to Anthropic’s Computer Use.
I imagine though, OpenAI’s agent, codenamed Operator, will be much better at completing tasks autonomously.
Why is OpenAI doing this?
In my opinion, Operator is a precursor to another massive OpenAI release that we won’t get anytime soon.
The OpenAI browser.
Is the internet really about to change?
In case you haven’t heard, the DOJ has ordered Google to sell Chrome. As of now, I’m sure Google is going to fight this tooth and nail, but there are any number of repercussions if this actually happens its hard to say what will happen.
One thing is for sure though, browsers and how we use the internet is definitely changing over the next few years.
One of the reasons for this is AI. Perplexity AI is already doing very good numbers and is one of the most valuable AI companies on the planet.
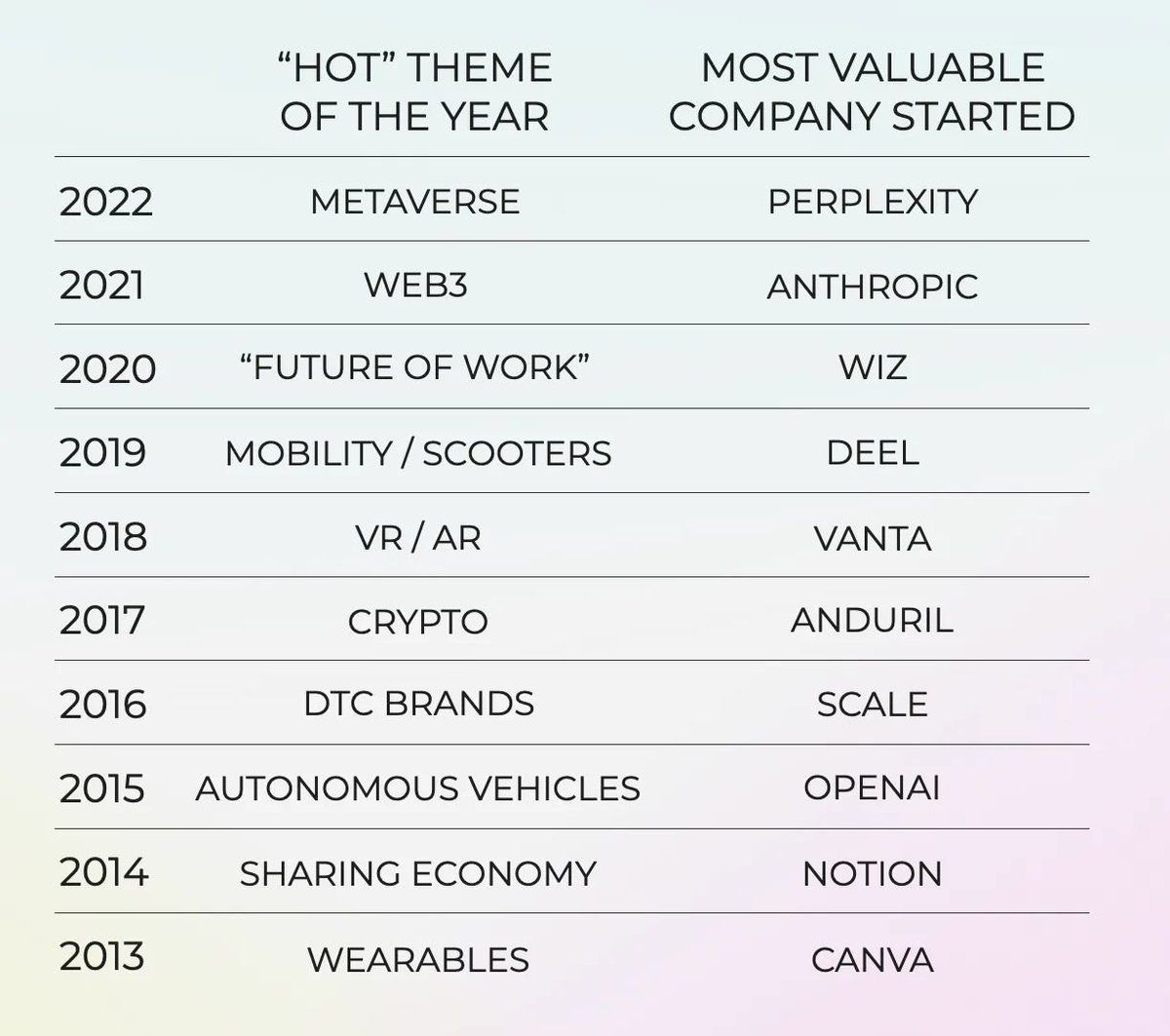
It makes complete sense that OpenAI would release their own browser. This is also being reported by The Information [Link]. (If anyone wants to buy a sub for The Info, let’s split it! I’ll share all the info x).
They have hired a number of people who helped build Chrome.
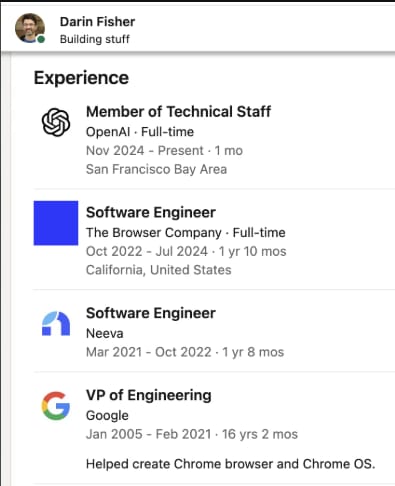
Not just Darin Fisher, but also Ben Goodger, a founding member of the Chrome team.
I don’t think a browser created by OpenAI will directly compete with Google. It will serve to create an entirely new paradigm.
Google Chrome was created from the understanding that speed and access to the web was the gateway to controlling digital attention.
OpenAI’s browser will be designed to rewire how human intention is mapped into digital actions.
Imagine a world where their Operator agent will connect to their browser to perform whatever task you want.
I don’t think this is too far fetched from what’s coming.
If you enjoyed this newsletter, please consider subscribing or contributing, it helps me keep writing more newsletters 🙏.
How was this edition? |
As always, Thanks for Reading ❤️
Written by a human named Nofil
Reply