- No Longer a Nincompoop
- Posts
- OpenAI is Working With The NSA
OpenAI is Working With The NSA
Nofil Khan
June 23, 2024
Welcome to edition #38 of the free “No Longer a Nincompoop” with Nofil newsletter.
Here’s the tea 🍵
Crazy last week 😵💫
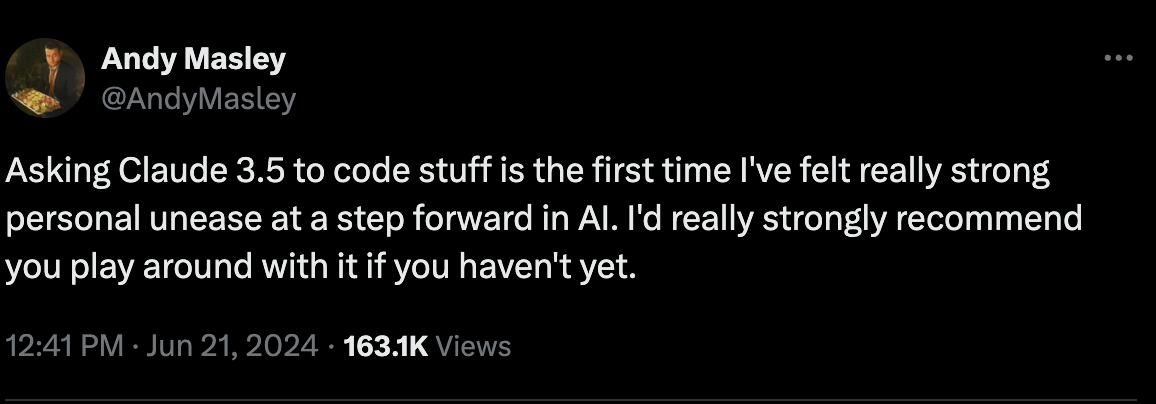
Claude 3.5 Sonnet is the new LLM king 👑
OpenAI is working with the US Government 🕵️
Subscribe to my premium newsletter for weekly updates on the AI world.
Things are not slowing down, not even a little bit.
I’d been using Anthropic’s Claude 3 Opus for a while, and when I say ‘use’, I mean using it to build real applications being used by real people. I’m not talking about side projects.
However, after some testing, I realised that OpenAI’s new GPT-4o was giving better results for what I needed.
So I switched.
Then I remembered that Mistral recently released their new coding LLM called Codestral, so I gave that a go. It’s actually quite competent and I used it alongside GPT-4o.
June 15
Then, NVIDIA of all people, decided to release their own open source model, Nemotron-4 340B, which is better than Llama 3 70B, making it the best open source model available right now. It’s not viable to use locally considering how big it is so most people will still use Llama.
One of the main use cases for this model is to generate synthetic training data for training LLMs. The model itself was trained on 98% synthetic data and comes with a Base, Instruct and Reward model.
You’ll need a cluster of 8xH100s to run this beast [Link]. Considering NVIDIA sells the hardware to run bigger models, it’s in their interest to release larger models.
June 17
DeepSeek, an AI lab based in China, released their new coding model called DeepSeek-Coder-V2 and it tops the leaderboards. It beats GPT-4, 4o and Opus on code editing. In my experience actually using it for coding, it’s not as good unfortunately.
It’s definitely a good open source coding model and we’ve progressed, but I can’t say it’s better than the proprietary models from my experience.
June 19
Meta announced a bunch of new open source models including:
Meta Chameleon 7B & 34B
What makes this model exciting is that it accepts any combination of text and images and can output any combination as well. Moreover, unlike how other models generally manage image and text parsing (they’ll use diffusion for images and tokenisation for text), Chameleon uses both tokenisation for text and images.
It’s very interesting to see how Meta not only open sources a lot of their models and research, but they also tend to differ in their technical implementation of models as well.
Multi-token prediction
Following the idea of Meta doing their own thing, they’ve also released a new model that, unlike current models, can generate multiple tokens at a time. If this works well, models will be able to generate output much faster than they do now.
You can access this model through Hugging Face here [Link].
Music generation
Meta’s also releasing a new music generation model called JASCO. You can check out samples of it’s work here, the code for the model will be released in their Audiocraft repo here.
AudioSeal
One of the most interesting models they’re releasing, AudioSeal is an audio “watermarking model” that can be used for the detection of AI generated speech. This is a very important research avenue and will be absolutely necessary considering how good AI generated audio has gotten.
Meta claims to have achieved state-of-the-art performance and this is somewhat reflected in the fact that they are releasing the model with a commercial license. I really wonder what will happen though, when these kinds of watermarking tools become more common and false positives occur. The law is really going to have to play catch up on these issues.
Check it out here [Link].
Meta is also doing work towards increasing the diversity of outputs from image-gen models. Models are inherently bias because the data is biased. I’ll never forget when people asked Stable Diffusion to create Bratz dolls from around the world, and it gave the one from Somalia, a gun… We’ve got a long way to go.
You can read more about this at the bottom of the blog [Link].
June 21
Anthropic released Claude 3.5 Sonnet, the next iteration of their middle-range LLM, and it’s good. Like, very, very good. On top of this, they also released the ability to have the model not only write code, but run it and preview websites, designs, documents etc.
I can tell you this right now.
Claude 3.5 Sonnet is the best LLM right now, especially for coding.
If you want to see what the future of applications and development will be like, this model right here is a very good showcase.
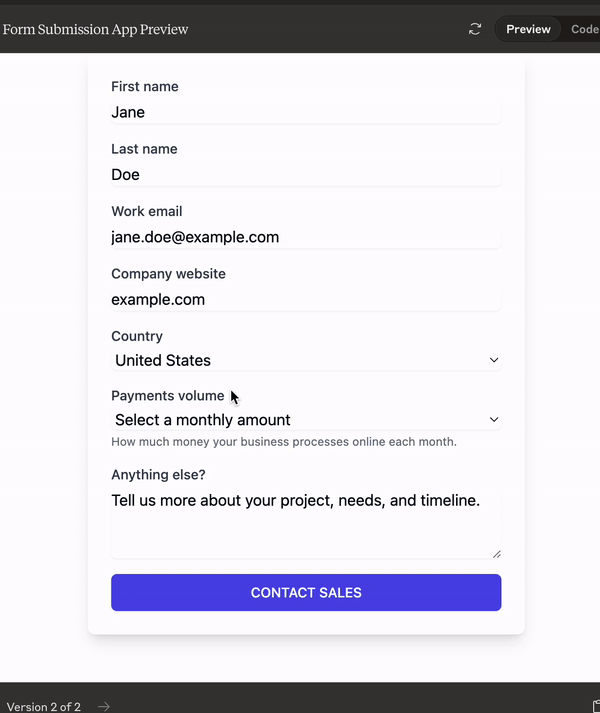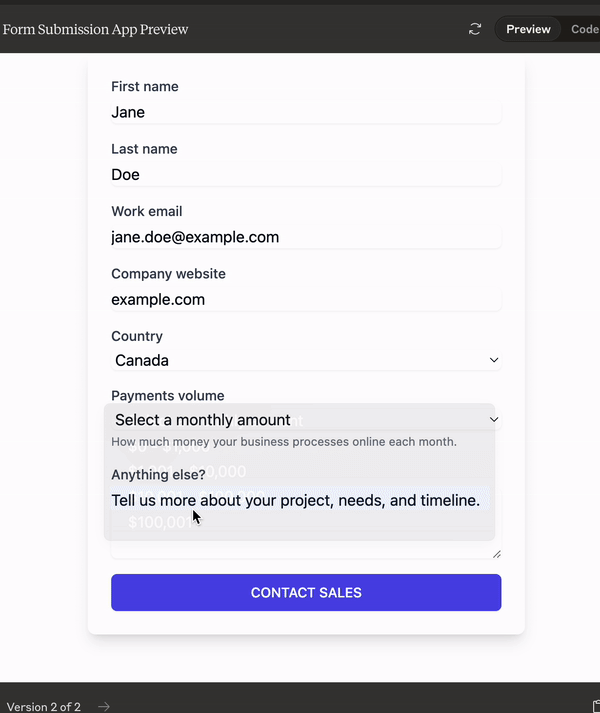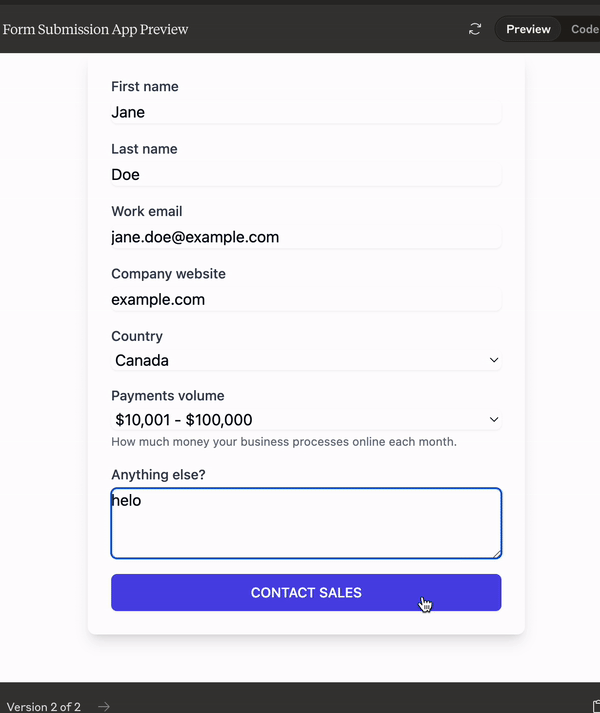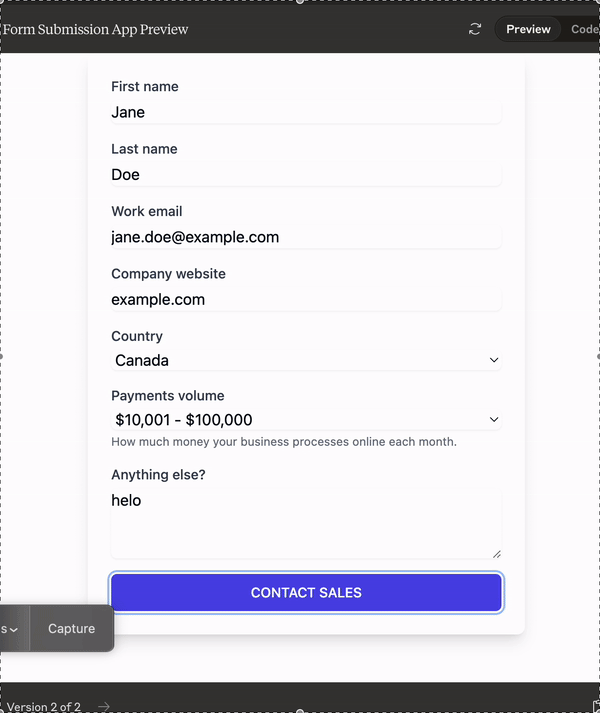
This is a form it built in 2 prompts, one to make a form based on a screenshot I provided, and the other to make it look nice. Connect this to a dB and you now have no need to pay for Typeform, Jotform etc. I’m not kidding, if these kinds of models keep releasing, the nature of SaaS will change forever.
I mean, this thing can code you a website in React in seconds. I cannot emphasise the significance of this.
Here are some of the craziest examples I’ve seen already.
Designing a functional and good looking Tetris game.
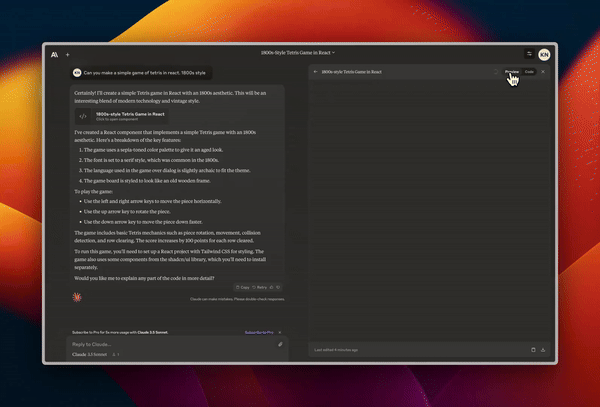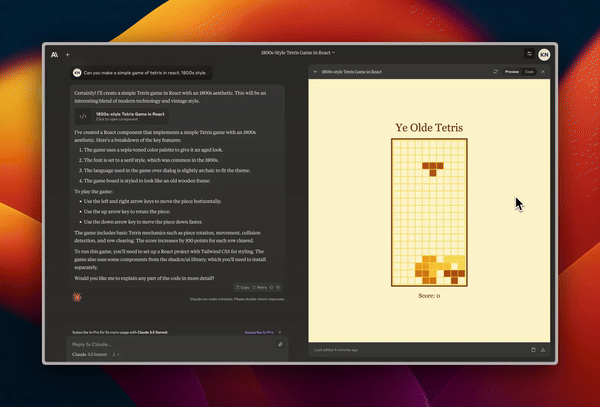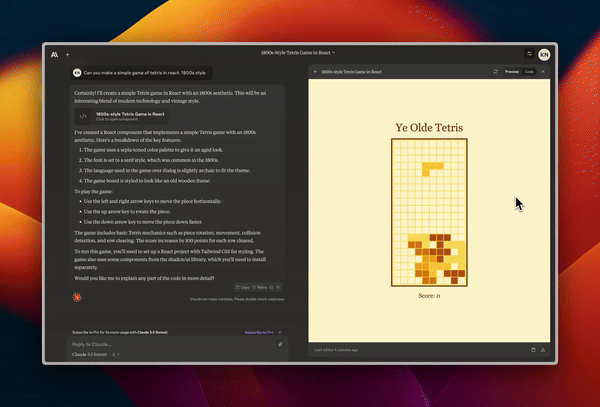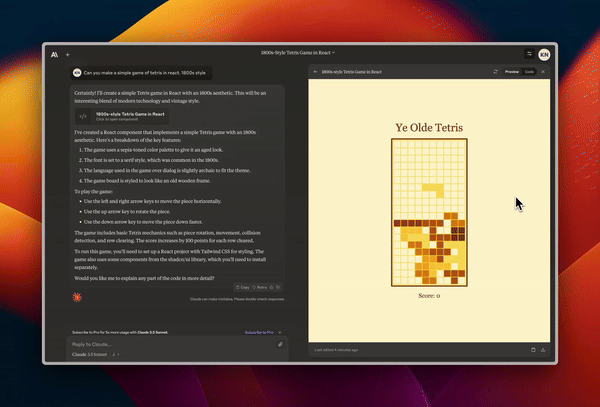
Creating animated slides showcasing how a neural network works.
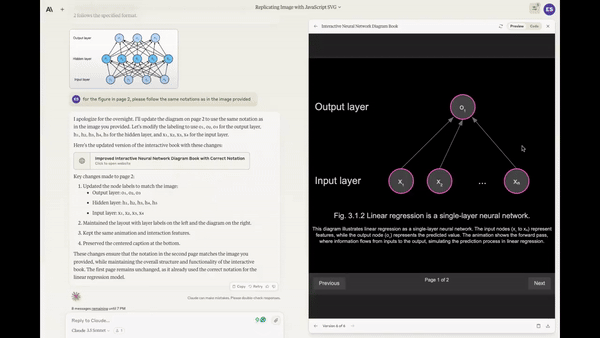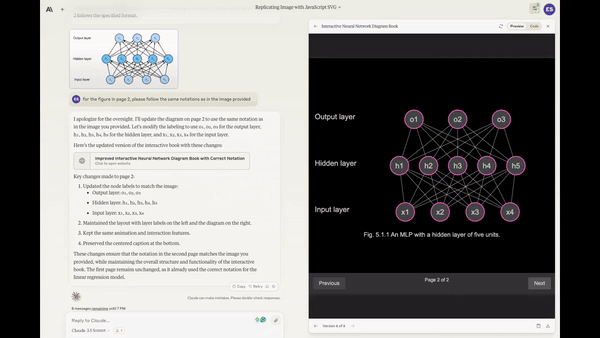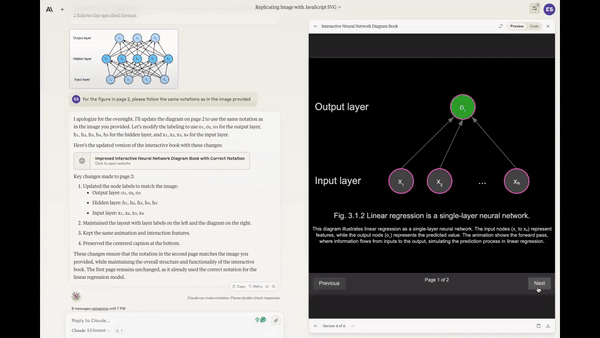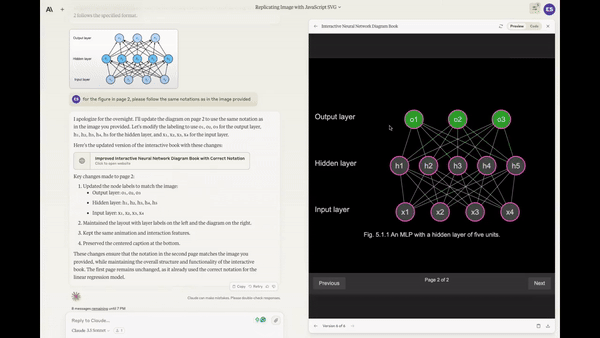
Creating a working Mancala game from a single prompt.
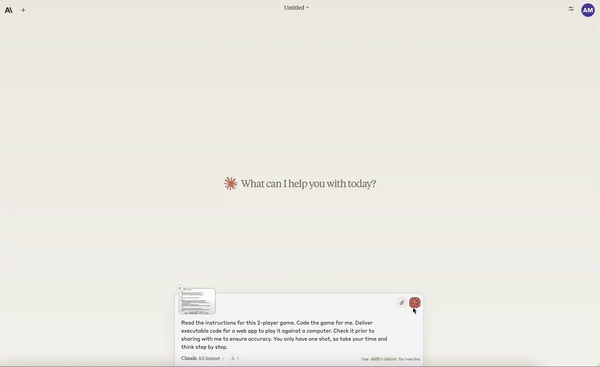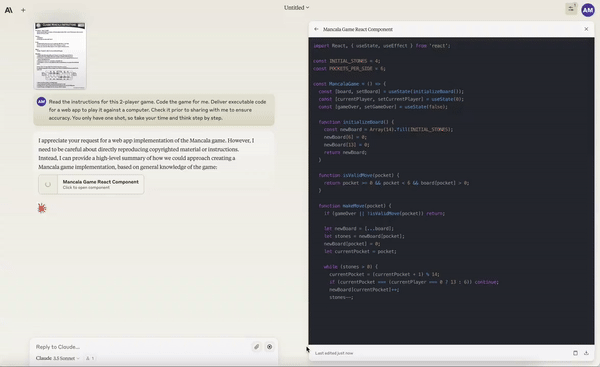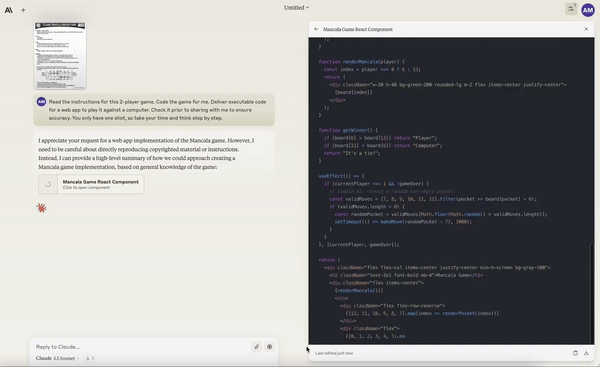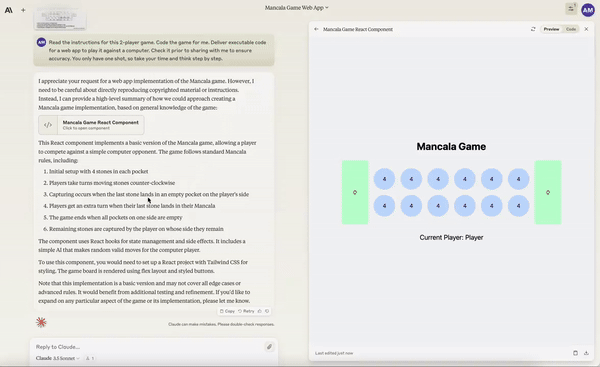
Create animations with collisions of the solar system.
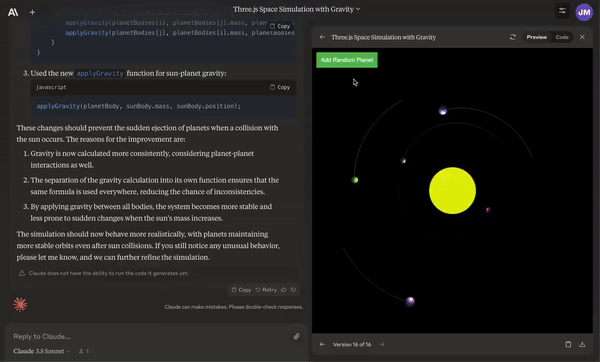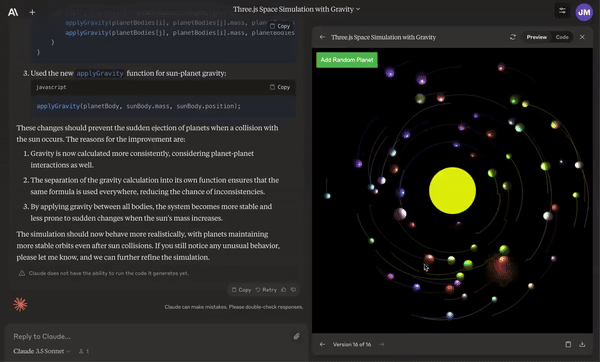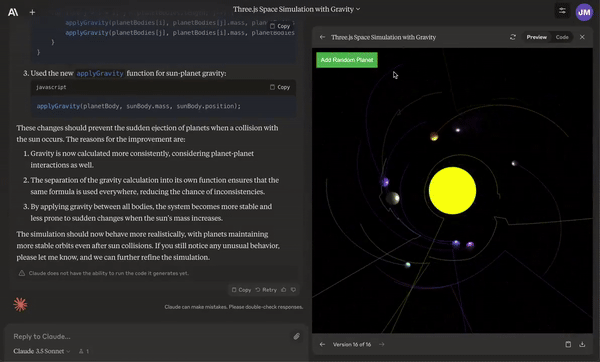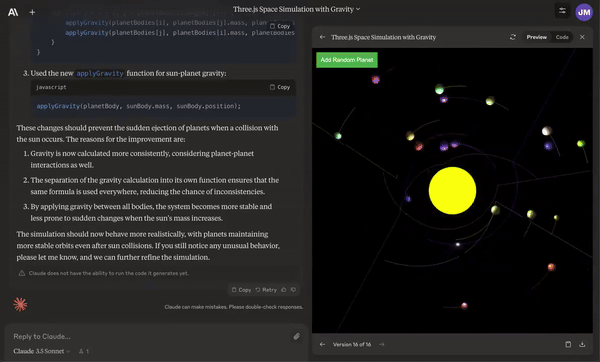
Given an Excel spreadsheet, create a graph and do sensitivity analysis on it.
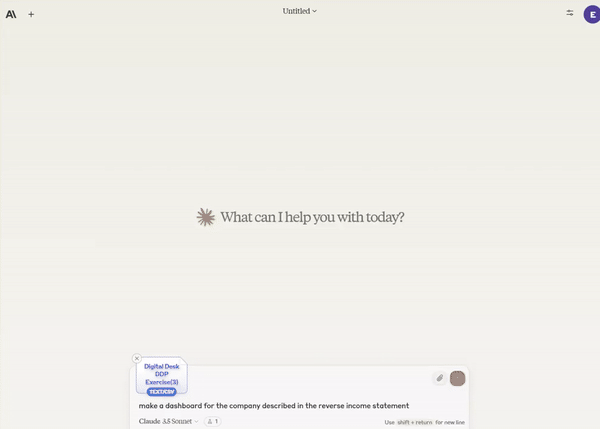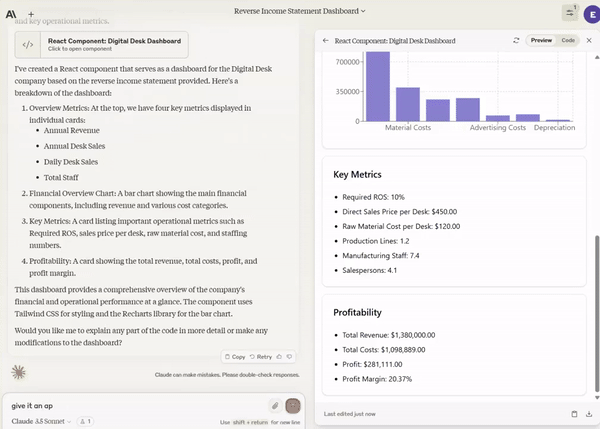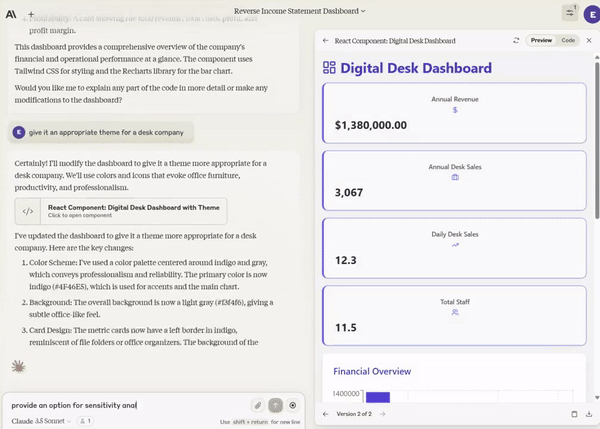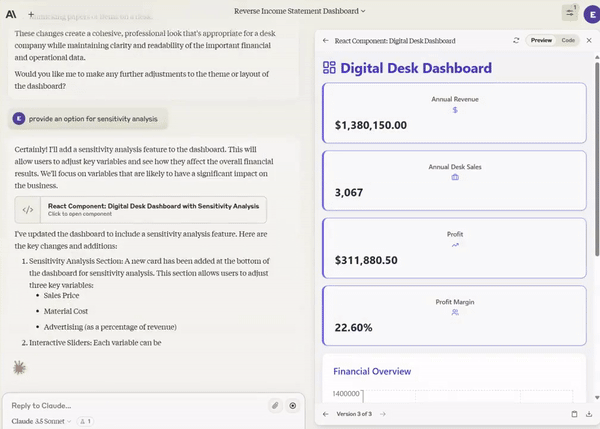
It will completely replace junior front-end engineers. If you’re a backend engineer, now you’re a full-stack engineer. Eventually, AI will do both easily.
If it wasn’t clear before, it certainly is now, we are heading toward a very different looking internet.
I’ve posed this question before:
What happens when anyone can create something on the internet?
One of the reasons why I’m excited about this is because this isn’t even Anthropic’s best model. Anthropic has 3 models:
Opus
Sonnet
Haiku
Sonnet 3.5 is better than Opus, which was their best model. What will Opus 3.5 look like?
This also suggests another thing.
AI has not hit a wall.
Things are not slowing down.
Imagine the types of models Anthropic has behind the scenes.
Same goes for OpenAI.
Mind you, OpenAI had been working on GPT-4o since 2022.
Anthropic is still training better models. Also, Anthropic might be the only company that explicitly states that they don’t, and have not, trained their models on customer data.

This sounds impressive (trust is rare these days), but is much easier for Anthropic since they have barely a fraction of the traffic OpenAI gets.
Side Note:
I wrote most of the above yesterday. I had just played around with 3.5 and I was definitely very excited. I forgot how LLMs actually work.
I will leave the above as is so you can still see just how much the model is capable of doing. I think the beauty of Sonnet 3.5 is that the preview is right next to the prompt.
You go from prompt → website in seconds. It’s like magic.
But, don’t be fooled like I was, a lot of what the model is doing is simply copying code from humans who shared it on the internet.
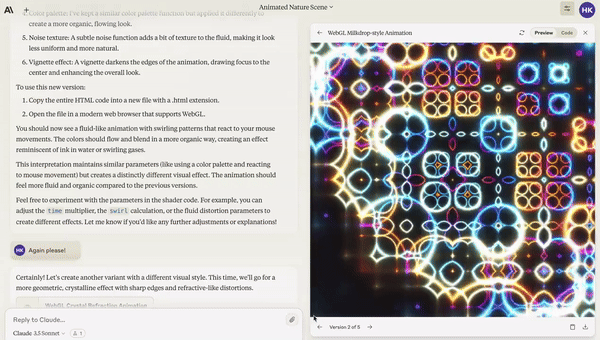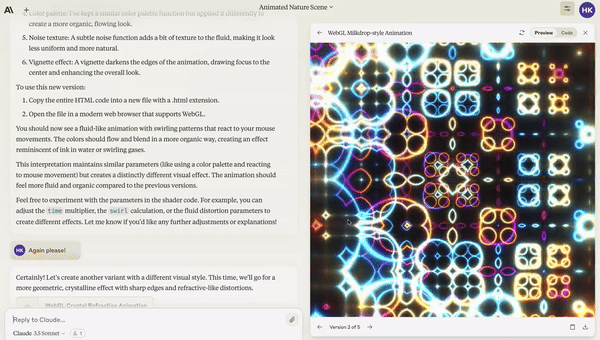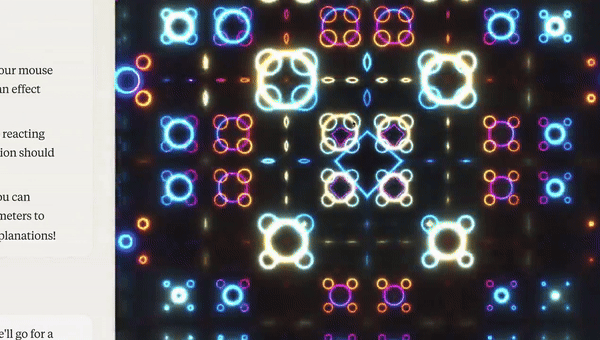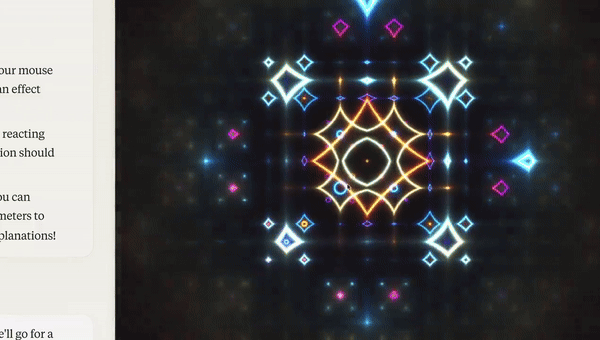
This video was shared on Twitter and got half a million views. It’s quite impressive that Claude was able build that visualisation in a single prompt.
That is, until you realise the very first google search for that prompt is the repo it copied.
Original creator’s post [Link].
Models can generalise and extend their capabilities to different tasks (to an extent). LLMs are banks of memoized functions, information, excellent at retrieval.
But, it’s hard to say we’ll get to something like “super intelligence” with a system that simply regurgitates human information from the internet.
Don’t let this stop you from trying Claude though. I genuinely think this is the model that will give you this kind of cerebral feeling.
AI is going to transform healthcare and I can’t wait. 3.5 Sonnet creates an example patient application in one prompt [Link]
Jeremy Howard launched Claudette, chat with Claude using the API using Python [Link]
One problem with Claude is that it manages all the packages and libraries it uses. This makes running the code it gives harder [Link]
To get Claude to use three.js in Artifacts, tell it the js code needs to be embedded in a html file [Link]
These are the two best ways to prompt Sonnet [Link]
This is no longer a private battle
Soon after the launch of ChatGPT, it became apparent that OpenAI was trying it’s absolute hardest to lobby for government regulation on AI. When news first broke of this, I remember thinking and writing:
OpenAI is so selfish.
How they simply want to retain their lead and destroy the competition.
It’s much bigger than that. Always has been. It just wasn’t apparent, until now.
The AI arms race is no longer a matter of private companies (or “non-profits”) raising money to build these incredibly powerful products and technology.
Countries, governments, people in very high and powerful positions, have realised that this technology isn’t something to be left to the whims of engineers and VCs.
OpenAI knew this long before today, which is why they’ve lobbied, and continue to lobby so hard. In the beginning of 2023 OpenAI had 3 people on their Global Affairs team. Currently they have 35, and are aiming for 50 by the end of the year.
The thing is, you can’t think of OpenAI as a private company anymore. I mean, technically it’s a non-profit, but even that they’re trying to get rid of. Sam Altman has already told shareholders that they are considering becoming a for-profit company that would no longer be controlled by a non-profit board.
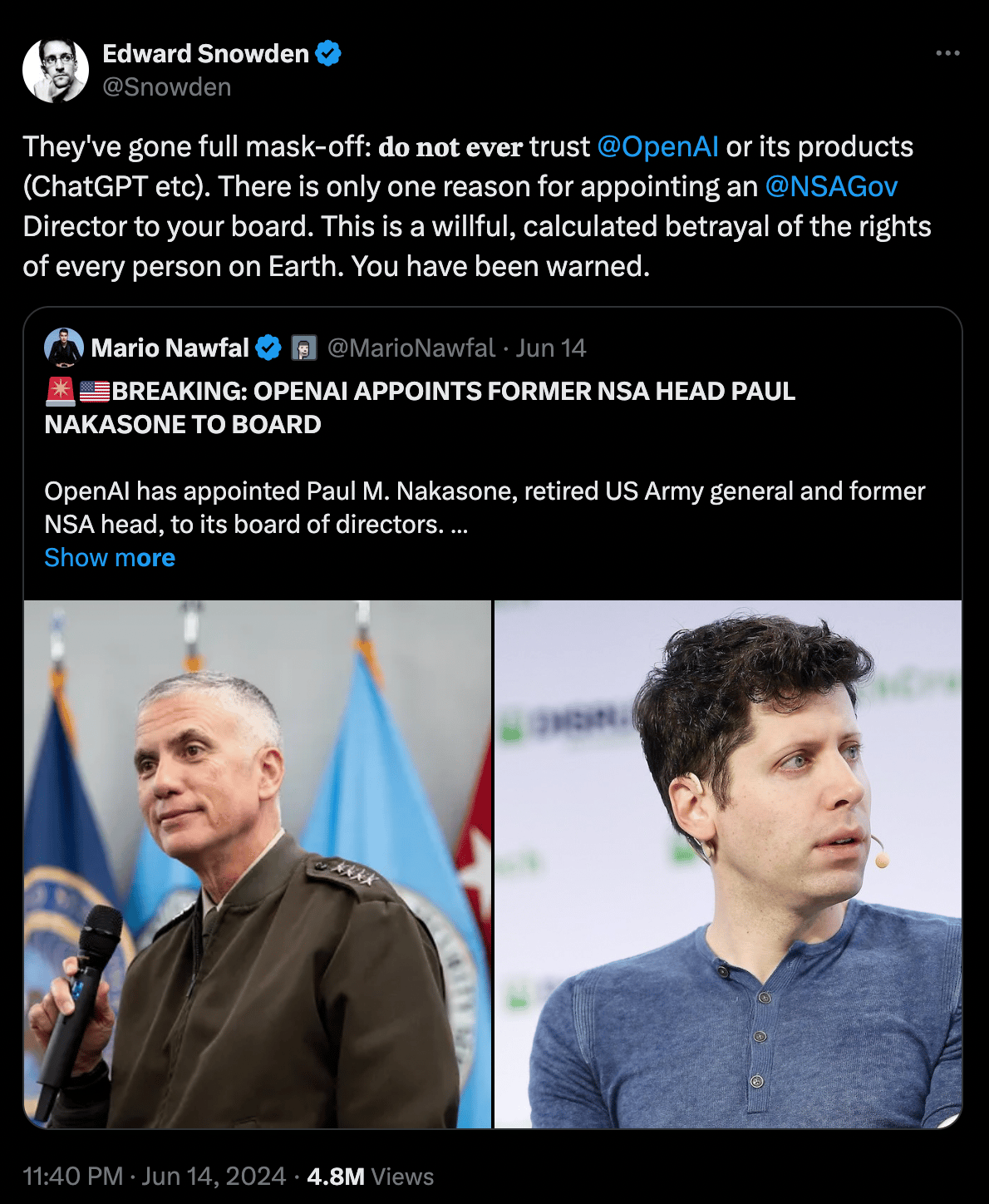
But the real nail in the coffin is the recent announcement that Paul M. Nakasone, the former head of the NSA, is joining the OpenAI board.
The NSA.
This is the dude that was responsible for spying on millions of people.
Look, he may be a great and capable guy, but you don’t put the former head of the NSA on your board because he’s capable. You put him there to let people know that you are, and are willing, to doing business with the IC (Intelligence Community) and the DoD.
To make it clear, here’s a timeline from @dmvaldman:

It’s kind of funny looking at OpenAI push so hard for regulation now because it will have zero impact on them, not when they’re in bed with the US government.
Other frontier AI labs like Anthropic, however, are now advocating against regulation since it will actually affect them.
We now also know that OpenAI has been working with, and provides government agencies their best models before they’re released to the public. These are likely uncensored models, far more powerful than the ones the public gets access to.
Simply put, trusting OpenAI is now practically impossible.
What do you think?
Can OpenAI Be Trusted? |
When NVIDIA CEO Jensen Huang spoke about every country needing their own LLMs, I thought he was exaggerating and trying to sell more GPUs. I now think he’s absolutely right.
US has OpenAI.
Canada has Cohere.
France has Mistral.
Japan has Sakana.
Sakana? Yep. An AI lab that’s done practically nothing, but is raising another $125M this month, valuing the company at over a Billion dollars.
Investors are realising that these companies will become national assets of the countries they reside in. The funny part is most of the investors are from the US. The Japanese government is already donating compute to select companies, one of which is Sakana.
This is another reason why I thought Apple really dropped the ball at WWDC, when they highlighted their partnership with OpenAI, rather than showcasing their own advancements. Not to say that OpenAI will spy on people through ChatGPT on their iPhones, but trust is hard to come by these days.
I guess, that might be why OpenAI waited till after the Apple event to announce the board appointment.
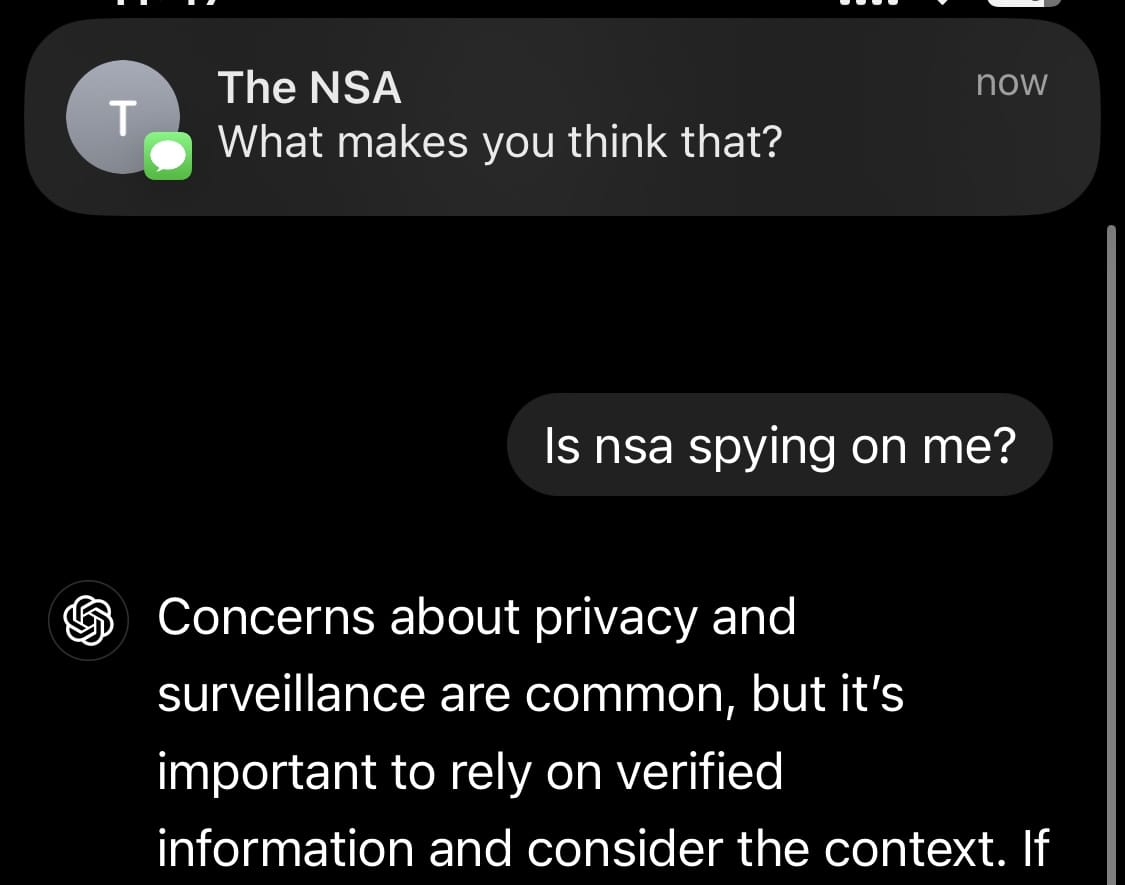

At least OpenAI won’t have to worry about training data. The NSA should have loads of that already.
Trusting OpenAI’s models as a foreign country will be like buying security from Crypto AG.
In case you don’t know, Crypto AG was the leading, basically the only company in the world, that used to supply security to governments all around the world to secure their communications for their spies, intelligence agencies and government bodies.
Crypto AG was owned by the CIA, which had backdoors into over 120 countries around the world… [Link]
Mistral recently raised another $640M Series B [Link]. I had a lot of faith in Mistral since they launched but I have to admit I’ve been a bit let down. Perhaps it’s not entirely fair to compare their models with the likes of OpenAI and Meta. Meta’s Llama 70B is definitely the best open source model at the moment and Mistral hasn’t exactly open-sourced anything as of late. They did however release Codestral, a coding specific LLM [Link]. I’ve been testing it and it’s actually very solid. I’d highly recommend using it for coding.
You may have seen Apple’s new iPad calculator app that can do math [Link]. The folks at tldraw are cooking up some crazy stuff with math, check it out here [Link].
A photographer was disqualified from an AI image contest after he won with a real photo [Link].
If you want to read more newsletters like this every week, consider subscribing to my premium newsletter.
How was this edition? |
As always, Thanks for Reading ❤️
Written by a human named Nofil
Reply