- No Longer a Nincompoop
- Posts
- The Closest to AGI We've Ever Been
The Closest to AGI We've Ever Been
Nofil Khan
December 21, 2024
Welcome to the “No Longer A Nincompoop with Nofil” newsletter.
Here’s the tea 🍵
OpenAI releases the strongest model ever - o3 👽️
Benchmarks 📊
Timeline ⌛️
Cost 💰️
How it actually works 🔩
I had two different newsletters drafted and ready to go and I had to scrap both of them to write this.
The amount of things announced and released over the last week has been astounding.
In case you didn’t know, OpenAI just finished up their “12 Days of AI” in which they announced something new every day.
We’re jumping right to day 12.
They just announced their latest “o” model.
The o3.
(If you read only one section of this newsletter, scroll down and and read “How does it work?”)
A step closer to AGI
Name
This is the first time since perhaps the release of GPT-4 that we can see just how powerful AI models have gotten.
To begin, let’s start with why “o3” and not “o2”?
Potential trademark or copyright issues with with O2, the British telco [Link]. So they’ve just skipped that number entirely.
What has it done?
The o3 is honestly our first look at what a potential AGI actually looks like.
It is, without a shadow of a doubt, the most powerful model ever announced and shown to the public.
Some benchmarks to begin:
Codeforces is a problem set designed to prepare competitive programmers. It is very hard. Some of the best programmers in the world rank atop its leaderboard.
o3 got a rating of 2727, putting it at the rank of International Grandmaster and in the 99.95 percentile of competitive programmers.
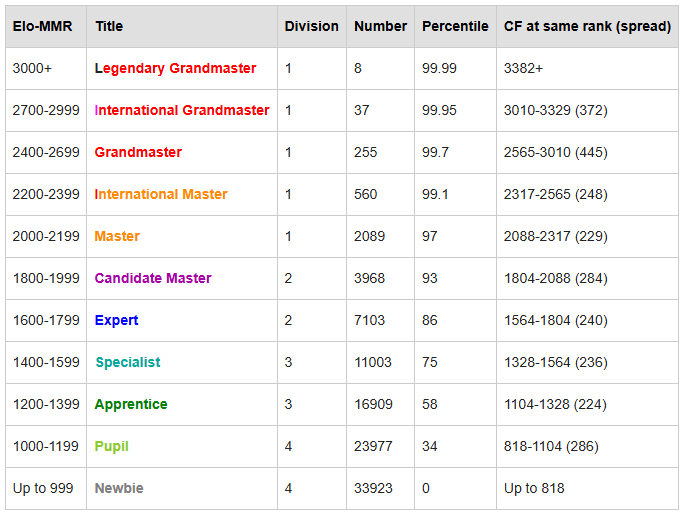
Mind you, while there are some competitive programmers who still rank better, o3 is better than them at practically everything else.
On the FrontierMath benchmark, we went from 2% to 25%.
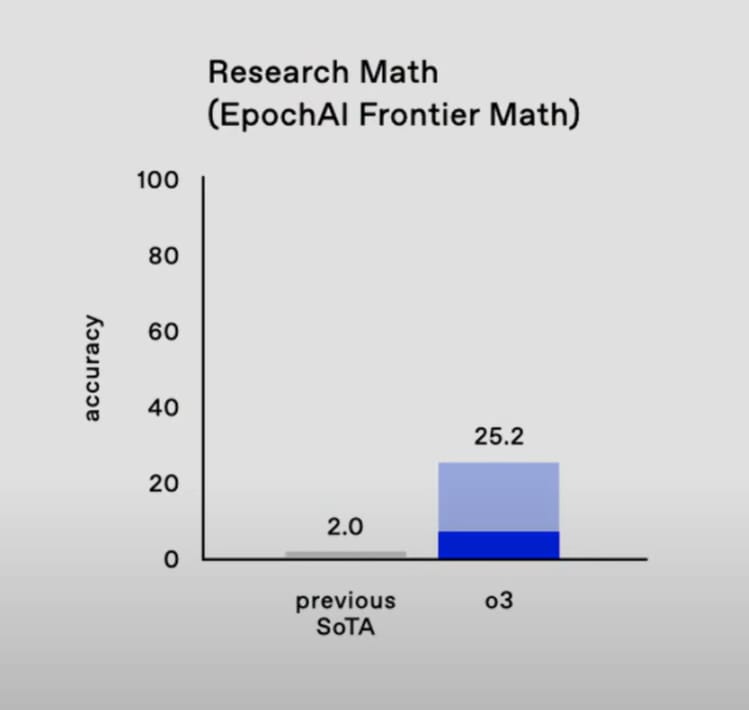
These are some of the hardest math problems on the planet, created specifically by mathematicians to challenge AI systems.
Only 5 questions are public, with the rest of the dataset being private.
Check out the questions here. Good luck, you’ll need it.
How about the ARC-AGI problem set?
For context, ARC-AGI was created in 2019 with the goal of measuring AI's general intelligence, specifically its capacity for skill acquisition in novel situations.
Essentially it measures adaptability.
It’s intended to be a benchmark where AI can be compared directly with human intelligence, focusing on tasks that humans can solve with zero/minimal training, but are challenging for AI systems.
There are two modes for o3:
Low-compute mode
High-compute mode
Low-compute meaning $20 per task, and high meaning any amount, thousands of dollars per task.
So, how did o3 do?
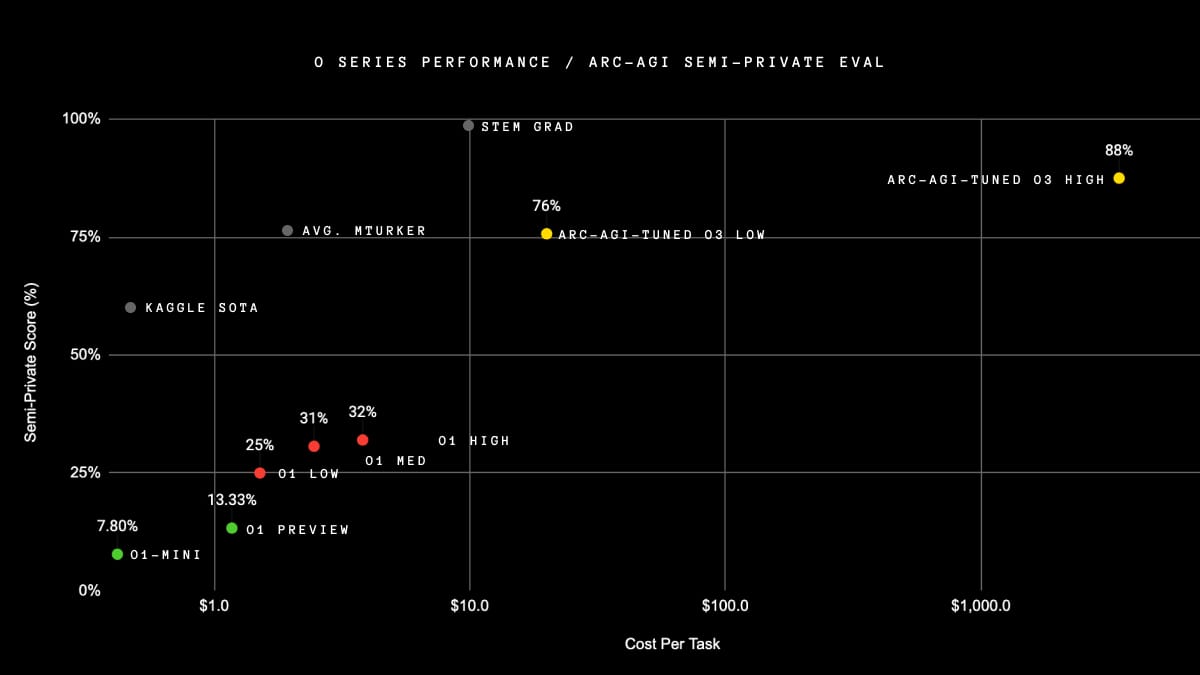
o3-low achieved a rating of 76% and o3-high achieved a rating of 88%.
It is hard to describe how significant this is.
First, let me show you how quickly we’ve gotten here.
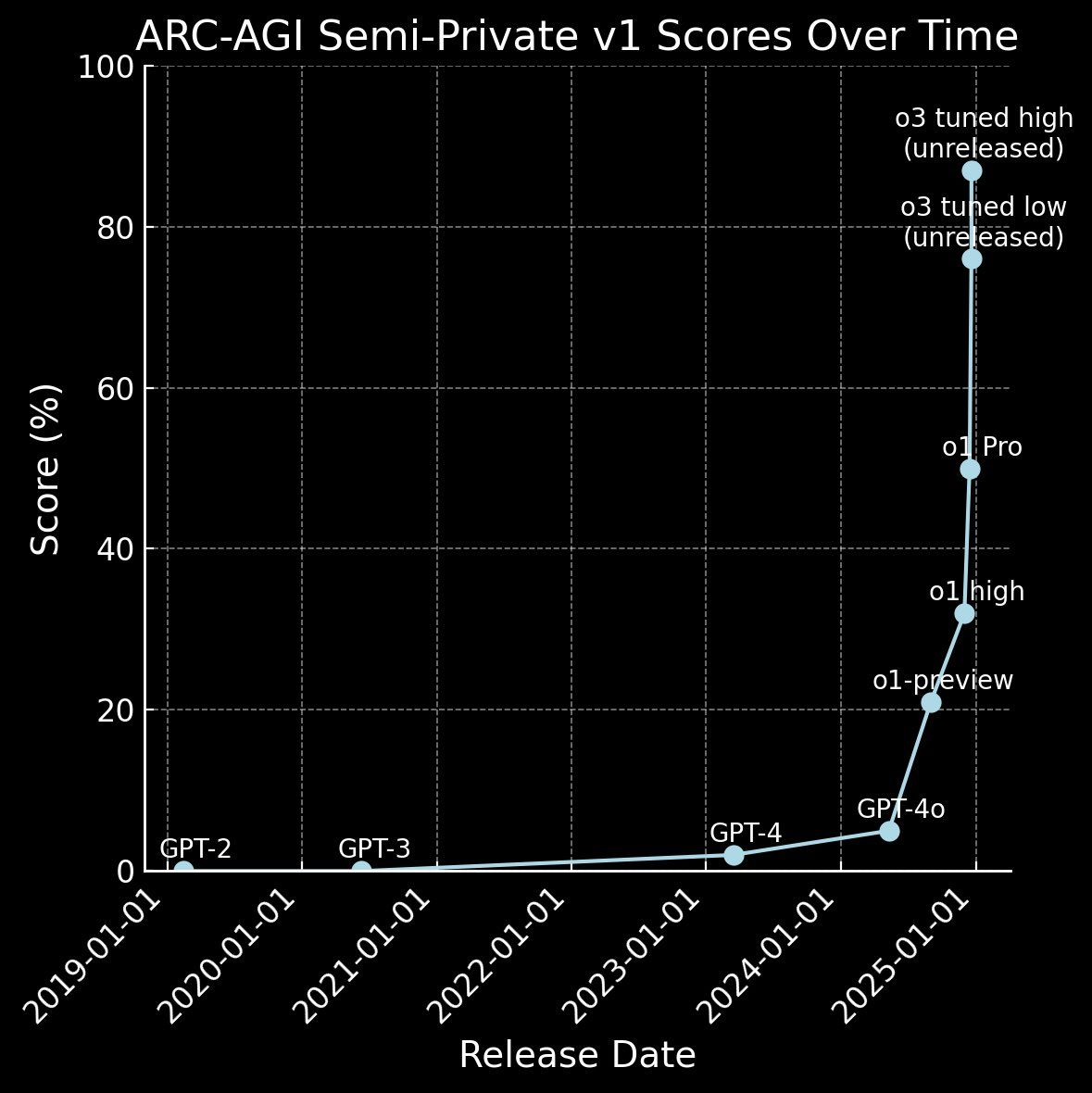
For years, we made zero progress.
In the last year alone, we’ve gone from 2% to 88%.
Do you see how fast we’re advancing?
But, it’s hard to understand how impressive this is without understanding how hard the questions are and what this means.
How well would the average human do on these tasks?
If you took someone off the street and asked them these questions, how would they score?
70-80%.
We already have an AI system that, for all intents and purposes, is smarter than the average human. Frankly many already thought this, but, we now have data to back this.
Do you know what the sentiment for ARC-AGI and AGI was two years ago?
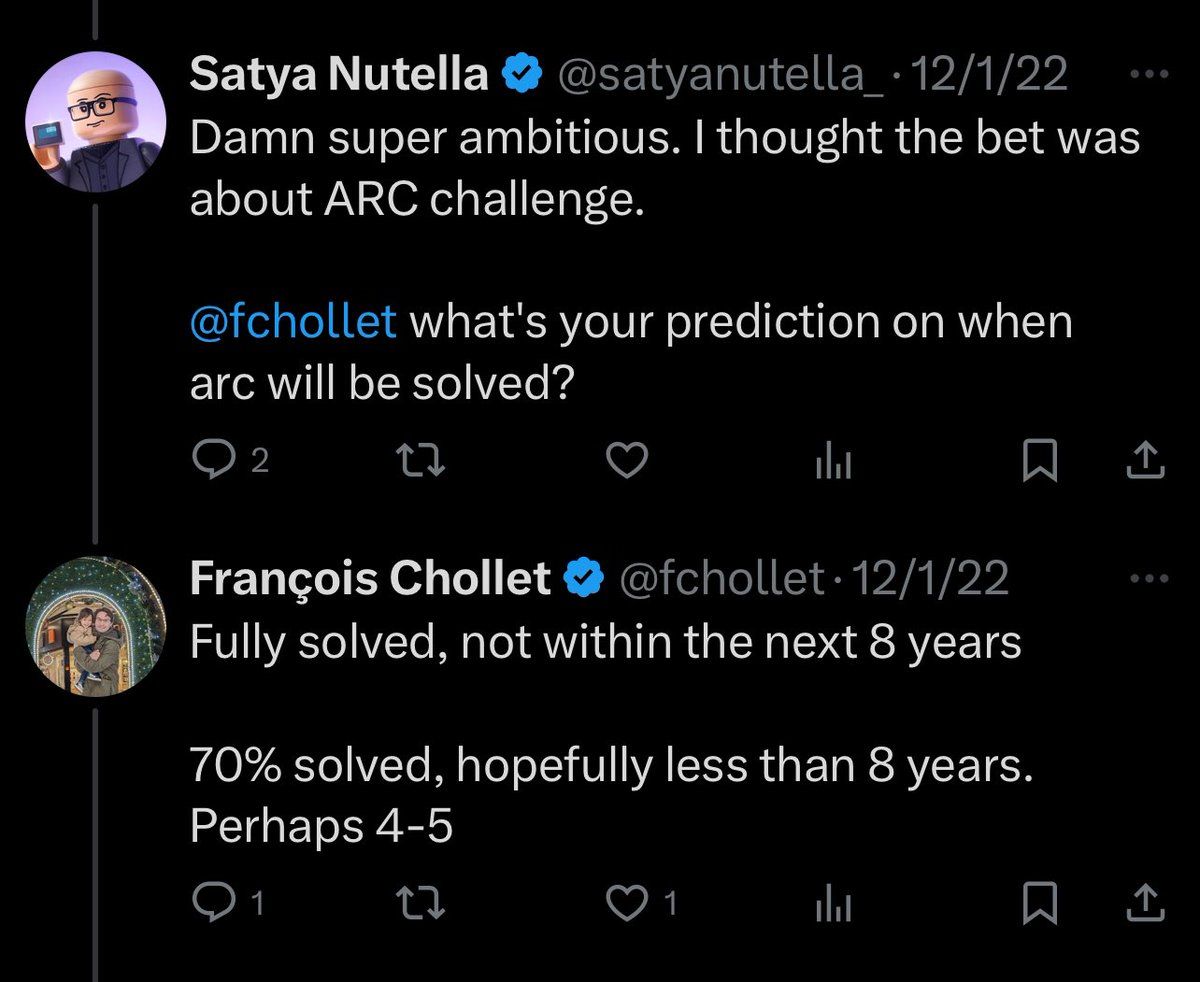
We are at 88% since this tweet. Will will solve it next year, possibly in the next few months.
Mind you, this is just OpenAI. We don’t know what Google or Anthropic have going on behind the scenes.
The goal posts have moved so much in the conversation surrounding what we consider to be “intelligent” AI systems.
But, surely we can’t just continue building these ridiculously powerful and intelligent AI systems, right?
I mean, you don’t just whip up a generationally powerful AI that breaks benchmarks we thought would stand for a decade.
Turns out it took OpenAI 3 months [Link].
3 months to go from o1 to o3.
3 months to build an AI that is smarter than the average human.
3 months to rank as the 175th best programmer on the planet.
There is no wall.
The reality is we’ve figured out a way to build insanely powerful AI, and, I think after two years I can confidently say this, we will definitively build AGI.
We will build an Artificial General Intelligence that will trump any human on any task.
I have not felt this this way since the release of GPT-4. We just reached a whole new level.
This is not a slow takeoff, this is a rocket ship
You might be wondering, is OpenAI just ahead of the game?
Are they the only ones who’ve got the right ideas?
No.
I’ll explain down below.
Caveats of the o3
Cost
Yes, the o3 is a monumental feat of engineering and a significant step towards AGI.
But, what are the caveats?
Well, first of all, o3 does its best work when it’s in “high-compute mode”. This means the model is allowed to use any number of tokens and power to find a solution to a given question.
What does this mean for usage?

The model costs well over $1,000 per task, perhaps around ~$2,900 [Link].
Per the blog, the low-compute mode cost under $10k which means it’s within the budget of the ARC-AGI prize.
The high-compute mode took 172x the amount of compute.
The cost?
~$1,600,250 [Link].
More than the entire prize pool.
Does this mean the most powerful AI models will only be available to the rich?
For now, yes. Until we have an open source alternative, the most powerful AI models and perhaps AGI itself will only be available to those who can afford it.
The rest of us will have to count the “r”s in strawberry by hand.
How does it work?
We don’t have a definitive idea on how o3 was able to achieve such remarkable results, but we can speculate.
I will do my best here to breakdown complex concepts around the way the system works to make it understandable to the average person (I’m the average person).
Much of what I will explain here is from the blog post by the author of the ARC-AGI challenge, François Chollet. You can read it here [Link].
So, we can think of traditional LLMs like GPT-4 or Claude like a giant library of “programs” or “patterns”.
When you ask them something, they try and find the closest matching pattern and apply it.
Think of this like having millions of cookbooks - they can follow any recipe they've seen before really well, but creating a totally new dish is hard.
New problems have always been incredibly difficult for LLMs. If a problem wasn’t in the training data, they couldn’t really solve them.
This is why GPT-4 was incapable of solving ARC-AGI (it got 0%). ARC-AGI was specifically designed to measure the adaptability of an AI.
It's like knowing how to solve every math problem you've seen in class, but struggling when faced with a totally new type of problem in the exam.
This is where the o3 comes in.
Previous models were like having really good memory.
The o3 does actual problem solving.
How?
What the o3 does is creates a number of CoTs (Chains of Thoughts). Once created, the o3 will go through a CoT and a different evaluator model will check to see if the CoT is promising.
If promising → keep exploring this CoT
If not promising → skip this one, go to the next one
What this allows the model to do is find promising solutions and explore them. Mind you, this also includes backtracking.
So, if the model finds a good solution and starts exploring it and then runs into a dead end, it will backtrack to an earlier point and go again in a different direction.
This way, the model can explore hundreds, even thousands of different possibilities before coming up with a final response.
If you remember, when I wrote about the o1, one of the problems it had was that if it thought for too long, it could reinforce the wrong answer to itself.
In this case, they have an evaluator model that is guiding it and allowing it to explore potential solutions till finds the right answer.
Is the model learning from its mistakes or wrong CoTs?
No.
It’s exploring different solution paths (different CoTs), and when the evaluator indicates a promising direction, it can develop that path further. It's not "learning" from failed attempts in any meaningful way - it's just abandoning unpromising paths and developing promising ones.
Essentially, the mode searches over the space of possible Chains of Thought (CoTs) which describe the steps required to solve a task.
Is this how humans solve problems?
Yes…?
Does the o3 "think" like a human? |
There are two problems François outlines about the model.
One - the CoT generated by the o3 are natural language instructions, meaning they’re just some text. They’re not written in code that the model can run and execute to see if it’s working as intended.
Rather, the CoT has to be evaluated by a different model, which lacks a grounding in “truth” so to speak, and could simply be wrong.
Second - o3 can’t autonomously understand how to create a Chain-of-Thought (CoT) and evaluate it. This means that the o3 is dependant on human annotated data around chain of thought and problem solving.
Simply put, the o3 learned its problem-solving approaches by studying how humans break down problems in their Chain of Thought explanations. It can't invent entirely new ways of solving problems - it's working with patterns it learned from human-written examples.
He compares it with AlphaZero (a chess AI) which can learn to play chess completely on its own through self-play, without needing human examples.
o3, on the other hand, needs these human-written Chain of Thought examples to know how to approach problems.
This means that it can't develop completely novel ways of thinking about problems, and, it's dependent on the quality and variety of human-written examples it was trained on.
This is everything I understood from my readings online.
This is all written in a more technical and perhaps more elegant way in the blog [Link]. Be sure to give it a read and let me know what you think of my explanation and how the models work.
I can’t believe I’m saying this, but, AGI by 2025 is looking like an actual possibility.
Arcprize is also looking for people to help them understand why high-compute o3 got certain questions wrong. This is quite fascinating because some of the questions it got wrong are really easy.
Like this one.
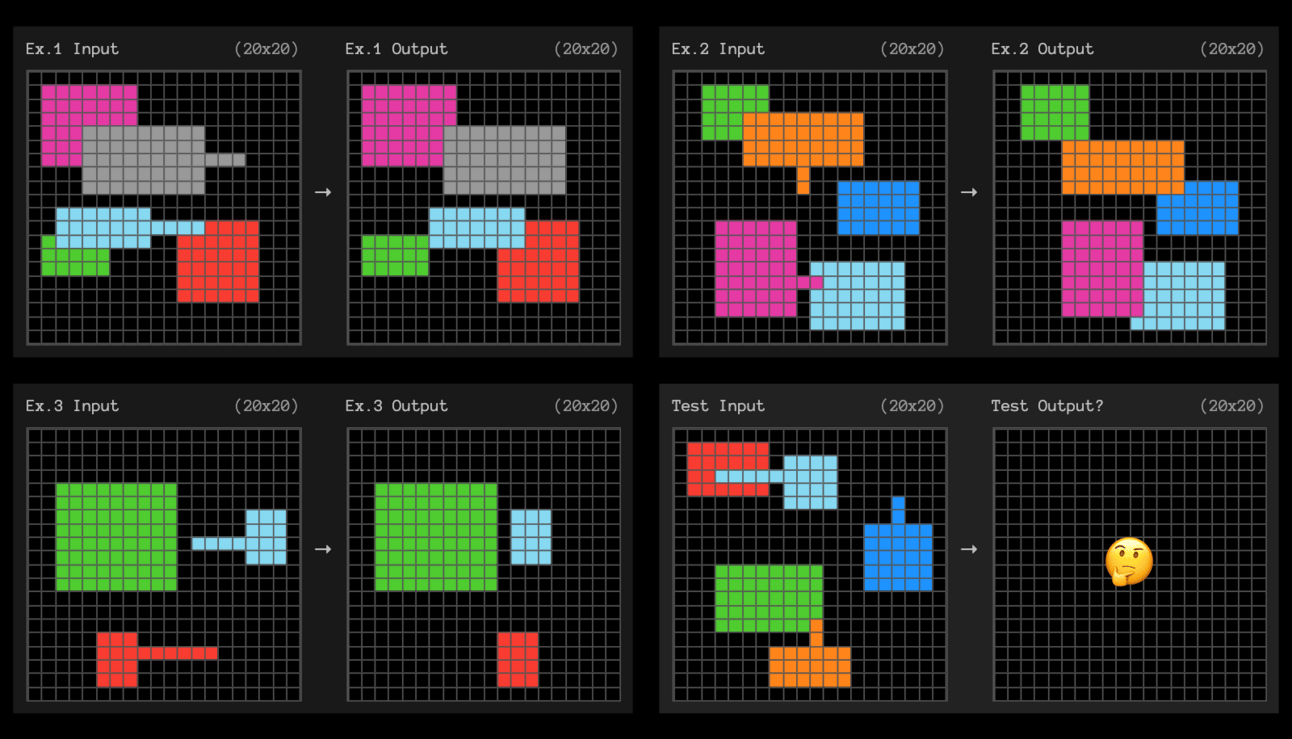
If we can figure out why or what the pattern is, we can accelerate open source alternatives.
Check out more about this here [Link].
Earlier, I said that the o3’s release doesn’t necessarily mean that OpenAI is ahead of the game. This is because Google mentioned researching this very concept last year [Link].
OpenAI is first to announce a new model using this new paradigm.
They certainly won’t be the last.
If anything, this makes me appreciate the human brain even more. It is a marvel, an unbelievable miracle that the brain can function at such a high level, so quickly, and with such little resources.
A true marvel of god.
I wrote this newsletter in a few hours after waking up on “holiday”. If you’d like to read more in-depth content like this, consider subscribing to the premium newsletter or simply contributing. It would help me write more :).
How was this edition? |
As always, Thanks for Reading ❤️
Written by a human named Nofil
Reply