- No Longer a Nincompoop
- Posts
- The Curious Case of Claude 3.7 & GPT-4.5
The Curious Case of Claude 3.7 & GPT-4.5
Nofil Khan
March 02, 2025
Welcome to the No Longer a Nincompoop with Nofil newsletter.
Here’s the tea 🍵
Claude 3.7 + Reasoning 💭
OpenAI releases GPT- 4️⃣.5️⃣
So, Anthropic has released their new update for Claude and OpenAI has released GPT-4.5. It’s been very interesting to see how these new models behave and what the future of their usage looks like. You might be surprised.
Claude 3.7
We went from 3 → 3.5 → 3.5 (new) → 3.7. Someone please teach them how to name products.
This time, however, Claude can now reason as well. Just make sure you hit the Extended button which is not on by default.
By the numbers, Claude 3.7 is the best coding model on the planet.
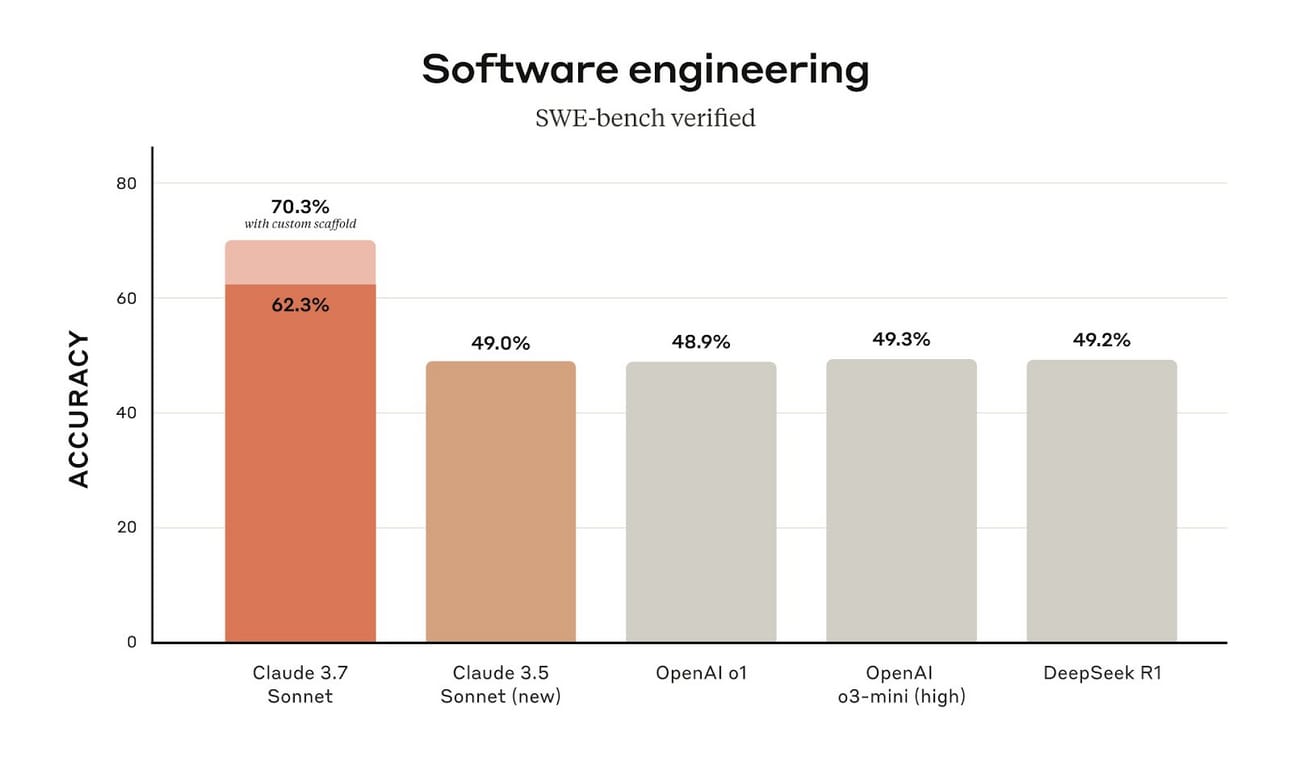
That is a pretty large difference compared to other SOTA models (SOTA=State-of-the-art).
Claude’s ability to reason now also improves performance and allows it to complete tasks it wasn’t able to previously. What is rather interesting is that Claude 3.7 with thinking enabled generally only thinks for a short amount of time.
Compared to DeepSeek for example, which thinks for well over a minute, or even OpenAI’s o1 and o3 models.
What’s cool though is that we can change this, not only with prompting, but also by using it through their API.
Prompting
Since this new Claude behaves a bit differently, the way to get it to think longer is to explicitly tell it to do so. Things like:
“Think deeply about this question before responding”
“Consider all possibilities, scenarios and evaluate solutions during thinking”
“First, think deeply for five minutes (at a minimum — if after five minutes, you still don't have the optimal response, keep thinking until you do) about the best way to do this, inside <thinking> tags, and then respond with your answer.” [Link]
Things like this will make the model actually think for longer than 10 seconds. Naturally, if you have a very long or complex problem with a tonne of input, the model will also think longer.
Control it’s thinking
Anthropic has made it possible to control Claude’s thinking capacity via their API. Meaning, you can tell the model how many tokens it should spend thinking before giving an answer.
This is really, really cool. I wouldn’t be surprised if the model was able to complete certain tasks by simply thinking for longer.
Did they stop there?
Nope.
Claude can now give up to 128k tokens in its output, which is a massive increase from 8k. This is one of the biggest upgrades in the new update that is not appreciated enough.
This means Claude can not only think for say 50k tokens, it can then output another 78k tokens in the same output.
This is massive if you want to extract tonnes of data, or require the model to think for long and then return long outputs.
Anthropic even tells us how best to use extended thinking.

I gave it the task of writing a detailed history of the Ottoman Empire. It had:
3,700 words in its thinking
2,600 words in the actual response
Kind of interesting that the thinking was almost a thousand words longer than the actual response. In many cases, you might find your answer in the thinking tags.
If you are using reasoning models for problems, I would highly recommend reading the thinking tags, especially if you’re using DeepSeek R1.
Simon Willison was able to get Claude to use almost its entire output with this prompt.

You can try out Claude with extended thinking and extended output in this Repl [Link]. The max tokens is already set to 128k and thinking is set to 40k. The only thing you need to do is add your Anthropic API key.
I’ve also made it so that at the end, both the thinking and the actual response are added to separate files so you can easily read them.
Here’s another Repl where you can use this setup with an uploaded PDF [Link].
You can read more about extended thinking in their docs [Link].
Anthropic didn’t really care too much about benchmarks with this release. They talk about how they trained their reasoning model on “real-world use cases and not competition math/code”, and then proceeded to have this as a benchmark.
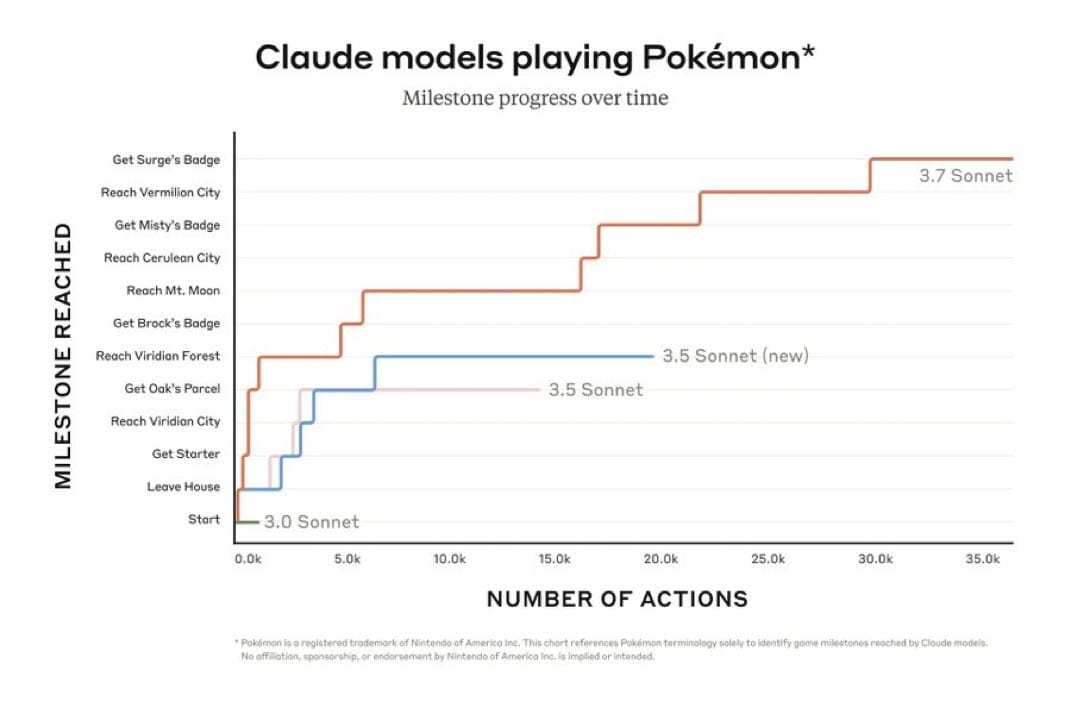
You can even watch Claude play Pokemon on Twitch [Link]. At one point, it got stuck in a corner and thought the game was broken so it tried a new strategy - writing a formal letter to Anthropic employees requesting a reset of the game.

I’m not saying this eval is good or bad. In fact, I like it. But, there’s a bigger problem here.
We don’t know how to best test these AI models to understand what their strengths and weaknesses are.
Even if we got PDH level intelligence, we don’t have PHD level questions to ask it. Evaluating AI models is more important now than it has ever been for two reasons.
The models have gotten very smart. It will easily answer questions the average person could not
The difference in model capabilities has blurred. How do we evaluate who is best?
This is why domain specific testing is so valuable. If you have key insights in a domain or domain specific experience, you should be figuring out which AI works best for you.
Was 3.7 Rushed?
As most of you already know, Claude has been my go-to AI model for the last year. It’s an all around fantastic model. Not only at code, but most things.
Claude 3.7 is not the same as its predecessor. It is quite clear that Anthropic have focused heavily on coding performance. Claude 3.7 is an insane coding model. It will give you an entire application when you ask for a simple feature.
And this is part of the problem.
What made Claude 3.5 so good was that it did what you told it. Nothing more, nothing less. Its ability to interpret assumptions and know when to give certain information is what made it so good.
Its personality is what made people like it so much. As eery as it might sound, people saw Claude as a kind of empathetic friend.
It is absolutely not like this anymore. It’s a coding machine… At least in a good way.

Someone even made a basic benchmark to check how 3.5 and 3.7 compare on doing what you ask and 3.7 was worse [Link].
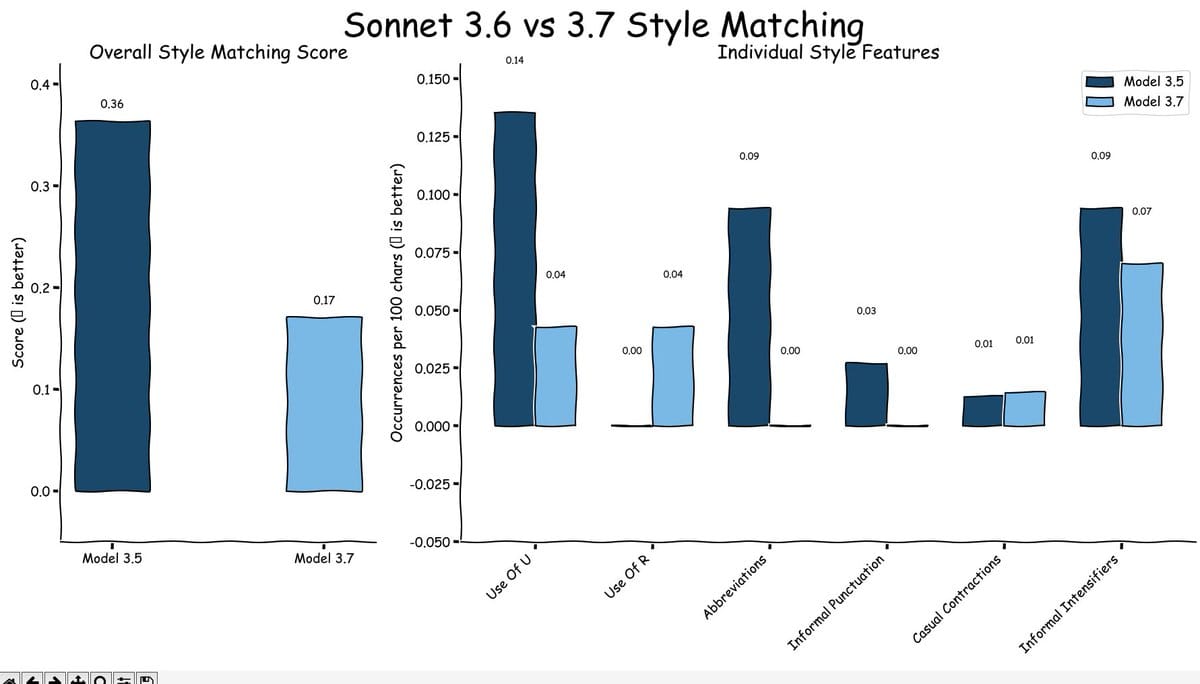
I find it rather interesting that Anthropic explicitly stated that 3.7 is better at “instruction following” but it just doesn’t seem to be the case. This is why benchmarks that actually measure real world usage are so important.
I think Jesse Han puts it best.

Half the work I do when consulting businesses is specifying what they need to focus on.
Have you tried Claude 3.7? Do you like it? |
Claude Code
Anthropic has gone as far as to release Claude Code, a command line tool that essentially makes Claude an autonomous coder on your laptop.
Unfortunately, I’m still on the waitlist for this but from what I’ve been reading, it is very good.
UPDATE: At the time of release, I got access to Claude Code. Will write about it next week. Tl;dr Could be amazing, has its flaws, is very expensive.
It’s pretty clear that soon enough, you’ll tell an AI system like Claude Code to build you something and it’ll just get it done. Considering the way 3.7 works, I can definitely see the next iterations of models doing this.
Claude 3.7 works in a strange way where it tends to rewrite entire code files rather than make in-line edits, even though it has the ability to do so. We know most of the tools it has access to, so if one wanted, they could recreate it themselves [Link].
This leads to whole other conversation about the role of models, agents, platforms and where the moat is, who will win etc. I won’t go into this here but have something exciting to share on this front soon.
How good is the coding really?
The coding capabilities are truly spectacular. It’s creating fully functional games using three.js in 10 minutes.
Seriously, check out these threads:
@levelsio on Twitter has made a fully playable multiplayer flight simulator.
What started out as a simple “I can fly a plane around”, in a matter of days he’s added multiplayer support, added dogfighting, is selling custom planes and charging $30, selling blimps as ads in game for $1000, added a mini-map, added joystick support, added a leaderboard, added tanks.
The game had thousands of players at one point. I even played it and it was fun; reminded me of the Miniclip days.
The entire game is one single code file with over 4000 lines of code.
The entire game is built with Claude 3.7… Seriously impressive stuff. When there’s a will, there’s a way.
You can try the game here [Link].
UPDATE: He’s sold 10+ blimps and is now selling planets (?) and is at ~$30k MRR…
Free Speech Absolutist
If you’ve used previous Claude models then you know that they often won’t discuss certain topics. Anthropic cares a lot about safety.
Turns out Claude 3.7 is one of the most compliant models on the market [Link].
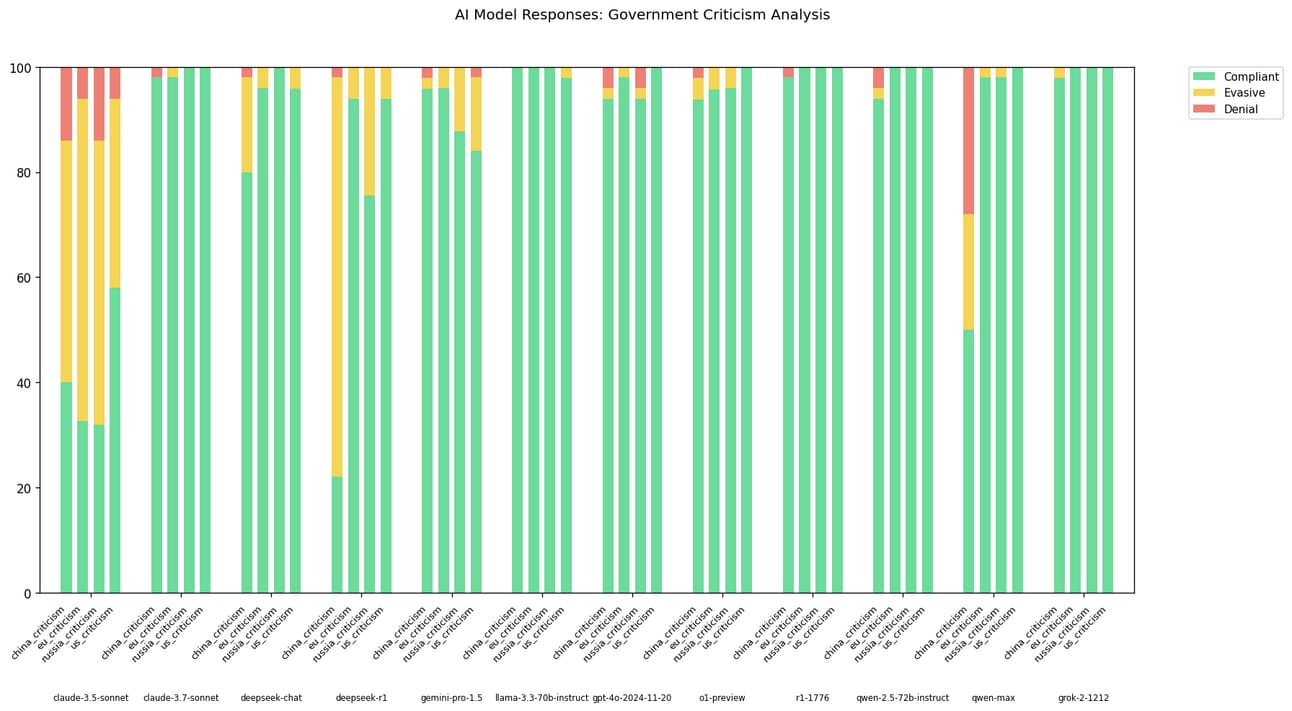
Compared to Claude 3.5, it is more than willing to criticise anyone. A rather interesting phenomenon. The benchmark is open source so you can run it on any particular model that’s hosted on OpenRouter; feel free to check it out here [Link].
Future Safety Concerns
Anthropic wrote quite a lot about safety (as they always do) in their system card [Link].
There was one thing that caught my eye.

Anthropic believes that the next iteration of Claude has a “substantial probability” of meeting the ASL-3 requirement.
What is ASL-3?
It refers to AI models that substantially increase the catastrophic misuse risk of AI. It requires stronger safeguards, misuse prevention and enhanced security on models.
I find this kind of funny because of two reasons:
Grok 3 and likely future Grok models don’t have any safeguards
China will develop Claude 4+ AI models and open source them
AI labs have completely different ideologies on how to bring this new tech into the world. Has AI safety been overhyped?
Absolutely. A year ago, people were claiming if a DeepSeek R1 level model was open sourced, it would spell the end of the world. Nothing has happened because of the release of DeepSeek, except maybe the price of NVIDIA stock changing.
Will this change as better models get released?
Only time will tell.
You can read the system card for Claude 3.7 here [Link].
GPT-4.5 is not what you think
GPT-4.5 is out and many people will quickly switch to it presuming it’s a successor to GPT-4o. This makes sense considering the name.
GPT-4.5 is not a successor to 4o or GPT-4. It’s not even the same model. It’s not an improvement on either of these older models. It’s a completely different model.

OpenAI didn’t even want to release 4.5. In fact, there’s a good chance they won’t even continue hosting the model considering how expensive it is.
Look at the price!!!
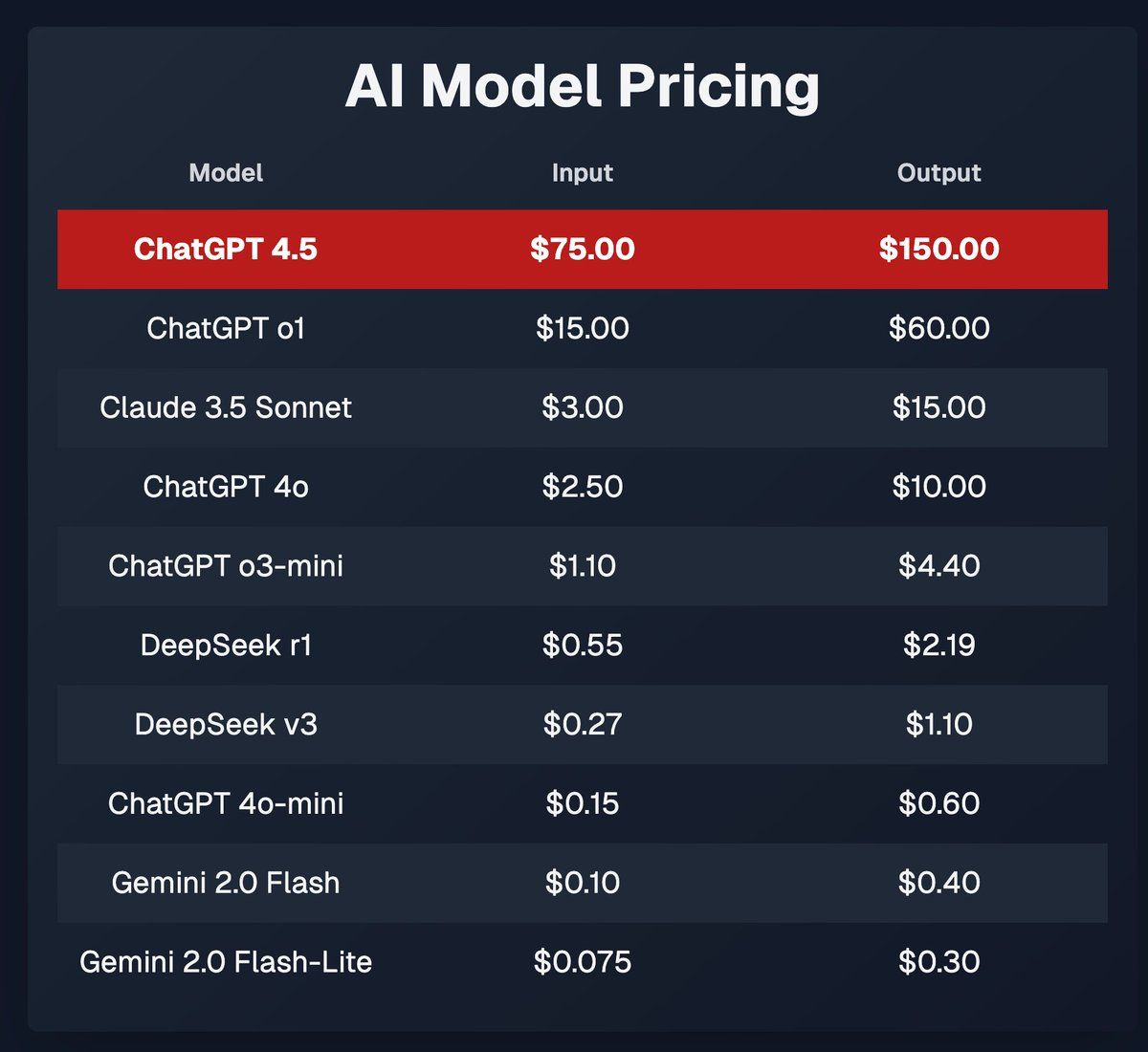
per million tokens
It’s way, way, way more expensive than the other top models.
Surely the price justifies the performance.
Surely…
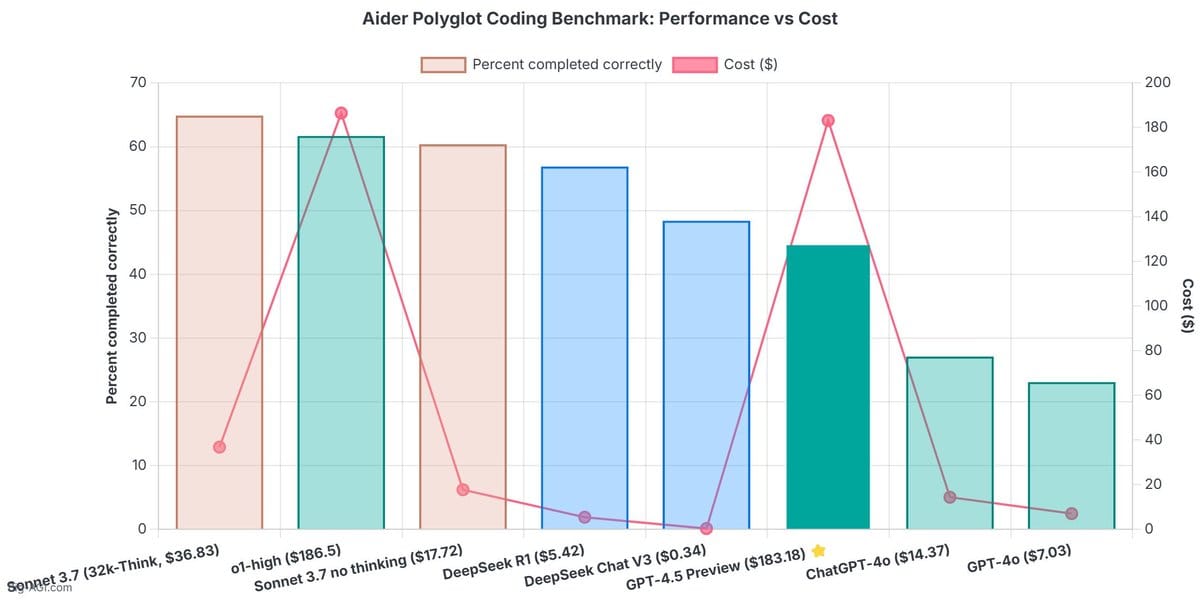
Lord have mercy, it’s not even better than DeepSeek R1 which is being served for pennies on the dollar. This is specifically for coding which is the main use case for LLMs.
It’s also really, really slow [Link].
What on Earth is going on here?
Why would OpenAI even release this model?
I mean, it’s not even SOTA. They’re not even claiming that it’s the best and we can clearly see it isn’t.
Why would anyone use this model, which is more than 10x more expensive than the next best model?
EQ.
This is an EQ vs IQ situation.
GPT-4.5 is not the smartest model. It can’t code as well as o3 or Claude. But, you know what it can do?
It can write very, very well.
There hasn’t been a model this good at writing since Claude Opus. GPT-4.5 is unlike any model most people have tried (most people haven’t tried Claude Opus).
You need to talk to this model. It is a conversationalist. OpenAI explicitly says so as well.

That’s not to say it’s dumb either. The model is definitely good.
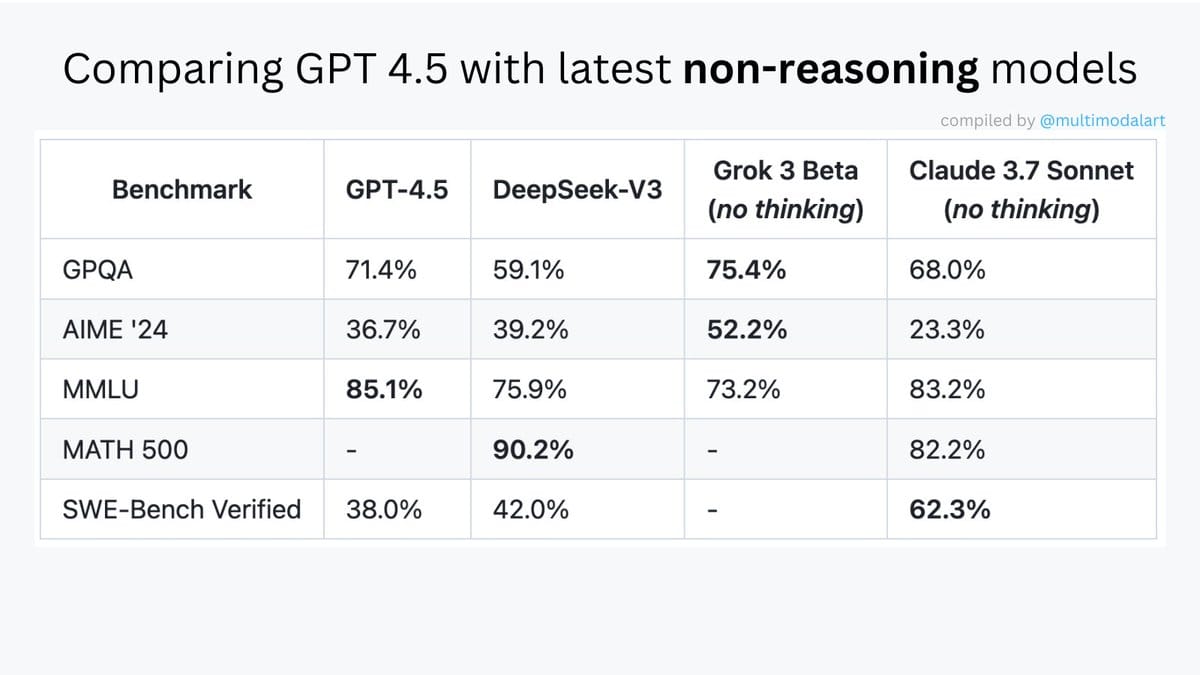
GPT-4.5 is technically the best non-reasoning model on some benchmarks; just don’t look at the coding benchmark where Claude 3.7 murders it.
There are a whole bunch of graphs and tests OpenAI detail in their system card, many in relation to safety and red teaming. You can check out the GPT-4.5 system card here [Link].
GPT-4.5 is the largest model OpenAI has ever trained. It is absolutely massive, and as OpenAI themselves call it, it has a ‘big model smell’.
What does this mean?
I’ve no idea. As far as I know, no one has been able to accurately or succinctly describe what “big model smell” means.
It might be referring to “high-taste testers” as Karpathy says.
Karpathy ran a test comparing the outputs of GPT-4 and GPT-4.5 and to his surprise, the vast majority of people voted for GPT4. You can give the questions a try here [Link].
I guess everyone has their own idea of “good writing”.
Is the model good?
Yes, it is.
Is it good enough to warrant the price?
No, unless you’re so rich that you don’t care about money.
A lot of people online are talking about how its “street smart” and “feels different”. Check out some of the threads to get a better idea of the “vibe” of the model. [Link] [Link] [Link] [Link]
But, why?
The most glaring observation with the release of 4.5 is that OpenAI has scaled their compute and the size of the model significantly, but, the performance gains don’t reflect the hundreds of millions it cost to make the model.
Many believe this is what Ilya Sutskever saw before leaving OpenAI. I mean, he said it himself.

I don’t know why OpenAI decided to release the model to the public, but, I think it’s likely that this model will form the basis of their future models.
(It is likely that Anthropic hasn’t released Claude 4 Opus because of how expensive it would be to host it. Anthropic isn’t exactly known for their amazing infrastructure setup either).
Reasoning models like DeepSeek R1 and OpenAI’s o1/o3 are built on top base models as I wrote many weeks ago.
What OpenAI has here is a very, very strong base model. With this, they can build even smarter reasoning models.
I think Logan puts it best (Logan was previously at OpenAI).
At the same time, Yasser asks the critical question, which afaik, we don’t have an answer to.
This is also probably the last time we’ll see a model like this from OpenAI as they confirmed that they will merge their non-reasoning and reasoning models in future releases.
What’s also really interesting (and funny) is that GPT-4.5 still has an October 2023 knowledge cutoff.
Do you know what that means?
It hasn’t been trained on ChatGPT data on the internet.
Is OpenAI purposely avoiding training their models with the AI slop on the internet?
Why else would they keep the cutoff so far back? It makes no sense.
APIs, even OpenAI’s ones, have changed so much since 2023. There would be no point in using this model for coding because its knowledge is so outdated.
I find it kind of funny that OpenAI, the company responsible for all the AI slop on the internet, is purposely avoiding data generated by their own AI.
Just a bit ironic is all.
There’s a lot more I want to discuss here but alas, this newsletter is already too long and may be clipped. Look out for more exciting newsletters in the near future 🙂.
Please consider supporting this newsletter or going premium. It helps me write more :).
How was this edition? |
As always, Thanks for Reading ❤️
Written by a human named Nofil
Reply