- No Longer a Nincompoop
- Posts
- The Most Significant Breakthrough Since ChatGPT
The Most Significant Breakthrough Since ChatGPT
Nofil Khan
January 27, 2025
Welcome to the No Longer A Nincompoop with Nofil newsletter.
Here’s the tea 🍵
China changes the AI landscape 🔥
How AI showed emergent behaviours 🫂
The politics of AI ⚖︎
The Stargate Project ⭐
Things are happening.
China’s done it again.
Chinese AI lab, DeepSeek, have released their long awaited R1 model. This model is a reasoning model competing with OpenAI’s frontier models like the o1 and o3.
There aren’t many words to describe what is happening, so, I’ll first set the scene with some numbers.
DeepSeek-R1 is on par or better than OpenAI’s o1 on most benchmarks.
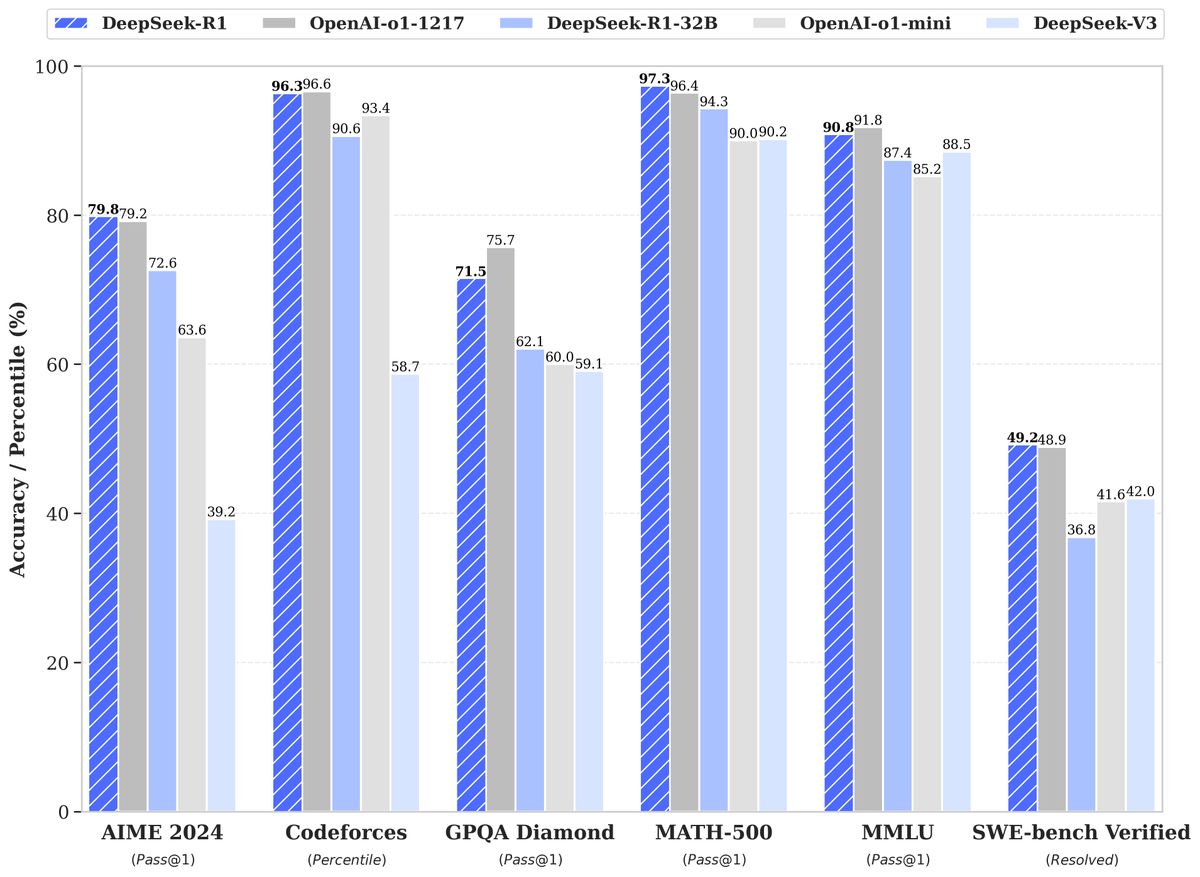
It is also 96%+ cheaper for both inputs and outputs.
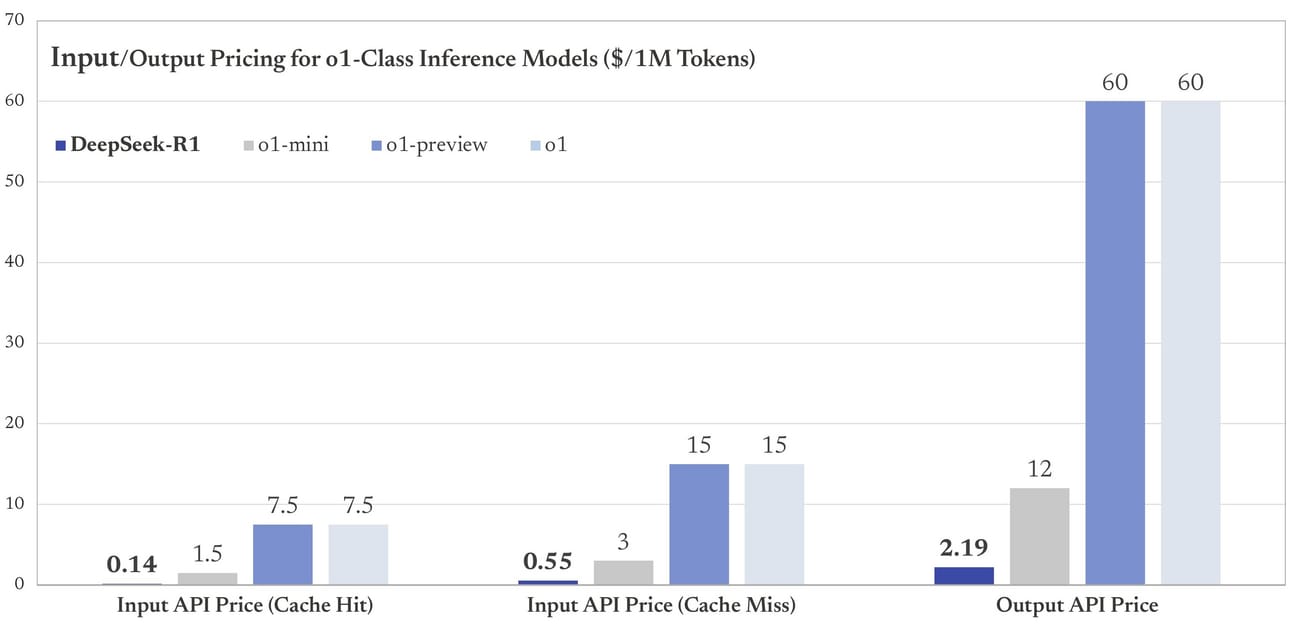
This is an open source, publicly downloadable and available model that is on par with the strongest closed source AI models on the planet.
The gap has essentially closed.
Intelligence too cheap to meter.
You know what the crazy thing is?
DeepSeek is doing what OpenAI was founded to do.
To push the boundaries of AI research and make it publicly available to everyone.
To democratise AI.
I can’t emphasise how significant it is that a company has open sourced such a powerful AI model.
Large organisations are worried, and rightfully so.
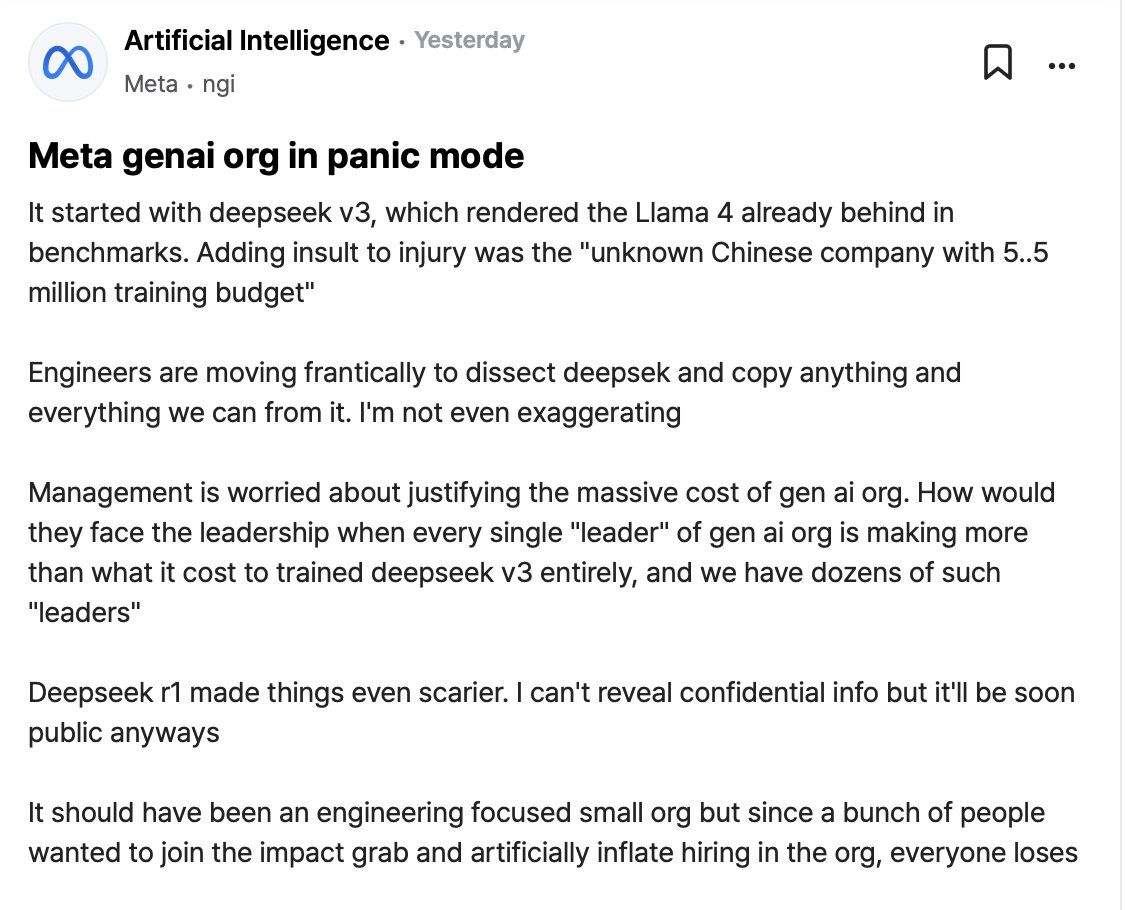
Why bother spending so much money building new models and buying 100k+ GPUs when a trading firm in China can produce better models for a fraction of the cost and release it to the public for free?
Notice how I said trading firm.
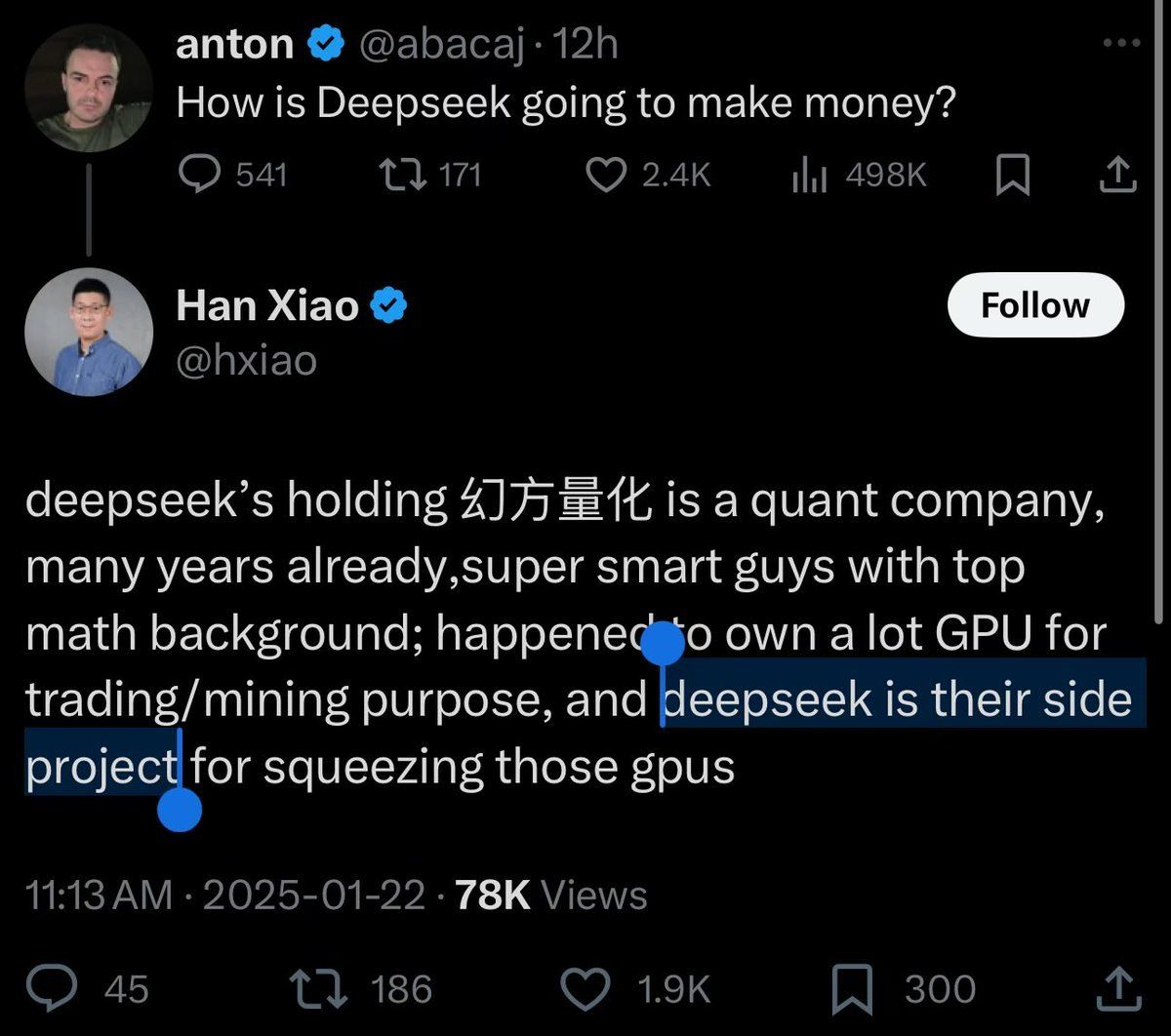
Now I wouldn’t go as far as to call it a “side project” considering they’ve spent tens of millions on DeepSeek and the paper has over 190 authors [Link].
Nonetheless, it is incredibly impressive.
They run a quant firm in China. The founder, Liang Wenfeng, also known as the “king of quants” in China, started DeepSeek because they had spare GPUs lying around and decided to make use of them.
They only started two year ago…
Mind you, it’s not like they released this model just to show us how good they are either.
What do I mean?
Models have licenses. Companies can restrict models to a research license, so it can’t be commercialised.
This model has an MIT license.
This means you can build a business with this model and commercialise its use however you wish. You can change it, modify it, copy and paste it, do whatever you want with it.
It also means you can use this model to make new models as well.
This is very, very important.
Why?
Because in their research paper, they used the R1 model to create smaller
“Franken-models” with other open source models like Qwen and Llama.
The results?
Astonishing.
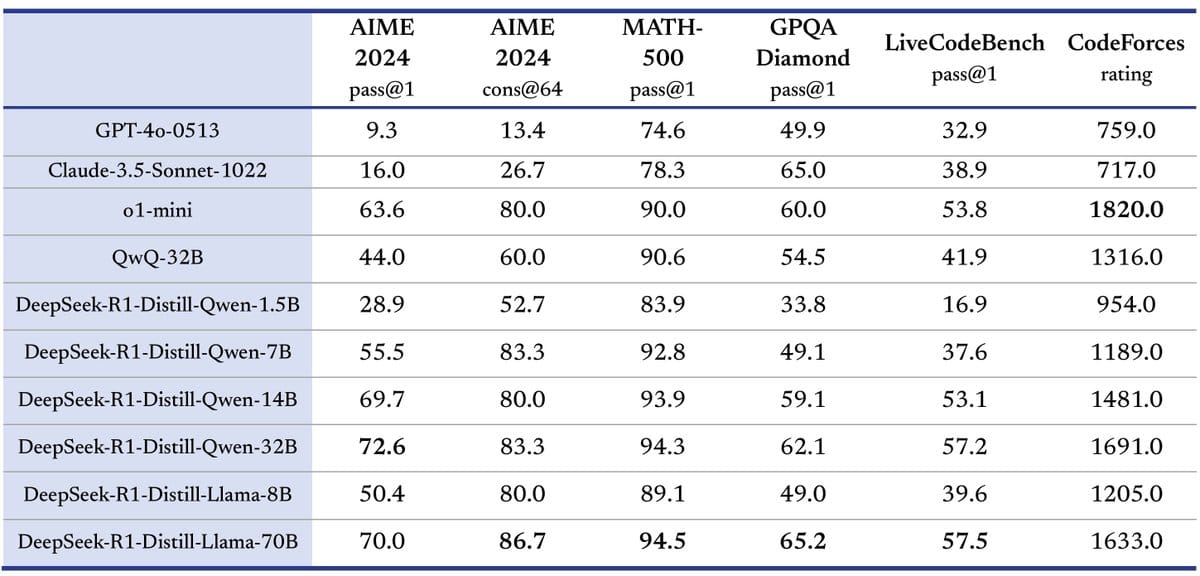
These are significantly smaller models outperforming some of the best models on the planet.
This process is called “distillation”, where you “teach” a smaller model to mimic the behaviour of a larger model.
You can run these on your PC if it’s strong enough.
You could even run the smaller ones on your phone, completely offline.
The implications are endless.
Do I recommend using these models?
Look, first and foremost, I would recommend using the original models that have been released. You can try the R1 on their website - https://chat.deepseek.com/, just make sure you have the “Thinking” button enabled.
These smaller models are for people who want to run models on their laptops and phones offline. I would not recommend using them for most people.
How to use the R1
Firstly, don’t use a system prompt. DeepSeek also suggest using a temperature between 0.5-0.7 (0.6 is recommended) [Link].
It’s likely the R1 doesn’t even have a system prompt at all. Just put everything in the user prompt.
On a lot of benchmarks, the best combination is to use R1+Sonnet.
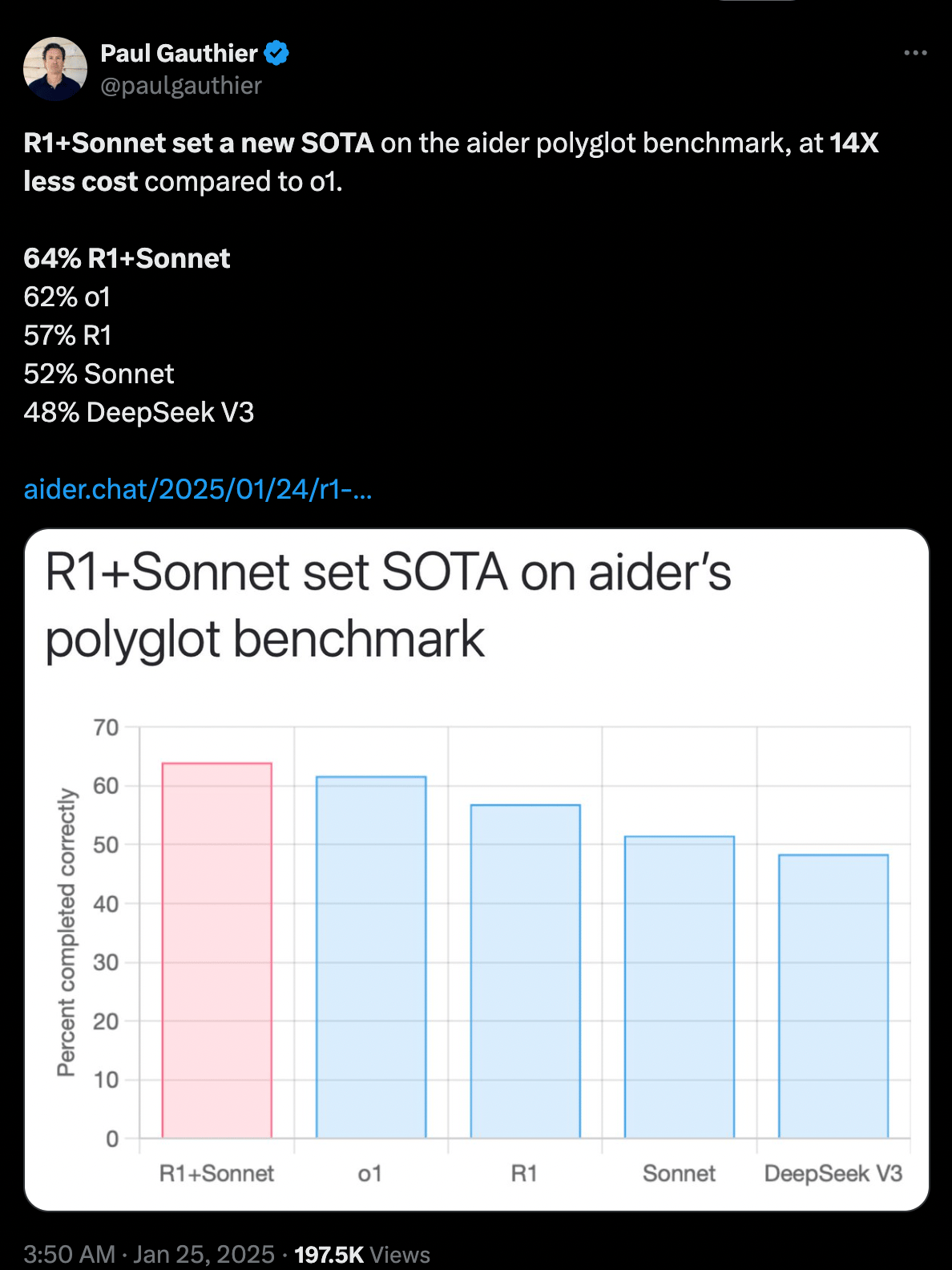
You can also take the “thinking” tags from R1 and feed them to different models.
You can use this tool to do so [Link]. I suspect it will increase capabilities of smaller models significantly.
Also, many people online are convinced, including myself, that DeepSeek with “Web Search” enabled is actually incredible. Better than ChatGPT Search and better than Perplexity [Link] [Link].
When using the R1, read it’s “thought process”. Then, come back and read the rest of this newsletter to see how it became able to “think” like a human.
You will be amazed.
Let’s talk about the research paper because there are some crazy things in it.
The incredible discovery
DeepSeek actually created another model, DeepSeek-R1-Zero, that they didn’t officially release.
Why?
The model had unpredictable behaviour, mixed languages together and was hard to understand.
But, the model itself was comparable to the o1.
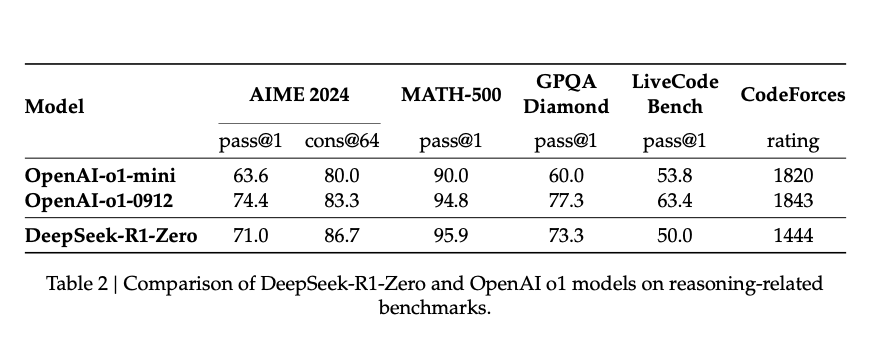
This model, DeepSeek-R1-Zero, and this research paper, might become one of the most significant releases in AI this decade.
This model was trained purely with Reinforcement Learning (RL).
Let me explain why this is so significant.
How AI is made and what makes R1-Zero so special
Supervised Fine-Tuning (SFT)
The vast majority of AI models are built using a technique called Supervised Fine-Tuning (SFT).
Think of SFT like teaching by example.
You show the model lots of perfect examples of what you want it to do.
Like showing it: "Here's a math problem, and here's exactly how to solve it step by step".
Most models are trained this way; they learn by mimicking good examples. All other AI models on the market right now use this method in some way during their development.
RL (Reinforcement Learning)
This is more like learning through trial and error.
Instead of showing perfect examples, you just give the model a reward when it does something well.
Like saying "try to solve this math problem" and giving it a point when it gets the right answer.
The model has to figure out HOW to solve the problem on its own.
There are NO examples provided, there is no guidance on HOW to do anything.
The “Aha” moment
Most state-of-the-art LLMs rely heavily on SFT.
They are pre-trained on a massive amount of text data and then fine-tuned with datasets to perform specific tasks.
DeepSeek-R1-Zero?
Zero SFT. None. Nothing.
This means no examples were provided. There was no program that said to the model “Here’s a problem and here’s how to solve it”.
There was no guidance.
They gave the model the questions and said “Here, figure it out”.
Guess what?
It did.
The model learned to learn.
With a simple reward system, the model, completely on its own, without any outside assistance or programming, showed emergent behaviours.
These were:
1) Reflection and Re-evaluation
The model started to exhibit behaviour akin to reflection, where it would revisit and re-evaluate its previous steps in the reasoning process.

Table 3, Page 9
The model explicitly states, "Wait, wait. Wait. That's an aha moment I can flag here. Let's reevaluate this step-by-step..." and then proceeds to correct its initial approach.
Unprompted, while solving this problem, the model decides to “wait” and reevaluates its approach.
2) Increased Thinking Time
As training progressed, DeepSeek-R1-Zero naturally learned to spend more "time" thinking about a problem before providing an answer.
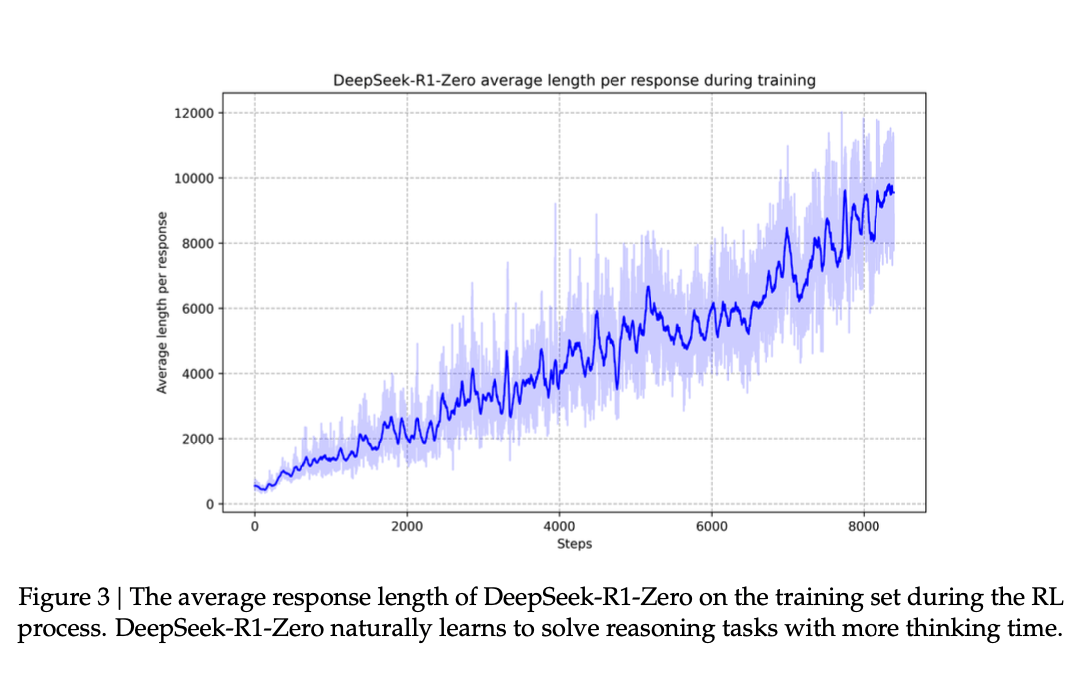
Figure 3, Page 8
It’s Chain-of-Thought naturally increased during training.
The model autonomously figured out that allocating more computational resources (generating more tokens) to the reasoning process led to better solutions, especially for complex tasks.
3) Exploration of Alternative Approaches
DeepSeek-R1-Zero began to explore alternative problem-solving strategies on its own, rather than sticking to a single, predefined method.
It developed an adaptable approach to reasoning where it explores a number of alternatives.
4) Self-Verification
The model developed some degree of self-verification capability.
Its ability to reflect and re-evaluate steps, combined with the "Aha, wait, wait, wait…" example, suggests that the model was learning to check its own work and identify potential errors.
5) Anthropomorphic Tone
It was an unintended outcome that the model just started talking and reasoning like a human.
“Aha”, “Wait, wait, wait”, "Let's reevaluate" and "I can flag here".
It’s talking like a consultant…
You can try the R1-Zero here - https://app.hyperbolic.xyz/models/deepseek-r1-zero.
It’s not censored either [Link].
Now, I’m not saying this thing is sentient or intelligent etc, but, it is truly astonishing that an AI can act this way without SFT.
Another reason why this model and paper are so monumental is because this has never been done before.
AI labs don’t try and build extremely capable reasoning models using only RL because they didn’t think it was possible.
This is the first time we have seen an AI model be trained this way and have such performance.
An unbelievable discovery and contribution to humanity to make this open source.
Cost and Resources
I feel like I should mention this because there is a lot of noise around this, and, well, if true, would be another monumental achievement.
There is a lot of speculation surrounding the cost of building the model and how many resources DeepSeek have, like GPUs.
The reason for this is because DeepSeek used their own V3 model as the base model to create the R1.
DeepSeek V3 was released in December, and according to the report, only cost
~$5.5 Million to build.
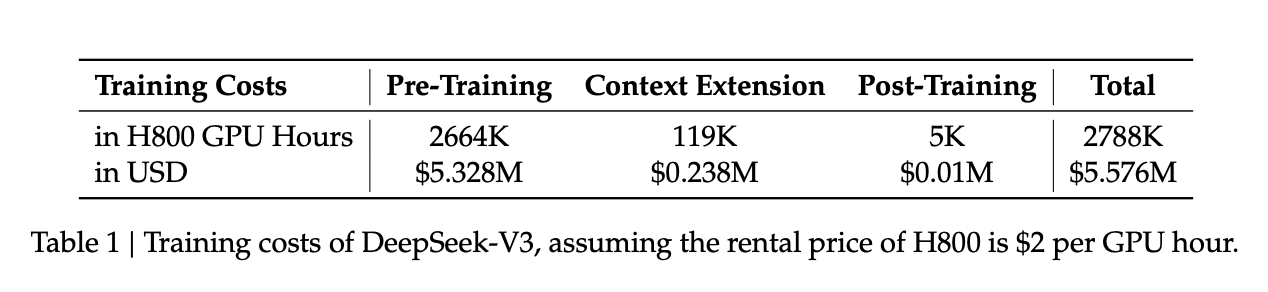
Page 5
That’s how much Meta pays like 5 engineers.
To make matters worse, they trained the model on only 2048 GPUs.

Page 11
If these figures are true, it goes directly against the direction of AI in the US. I’ll talk more on this in the next section.
We’ll just have to wait and see if anyone can mimic what they’ve been able to achieve.
There is already some very promising initial work being done in this space.
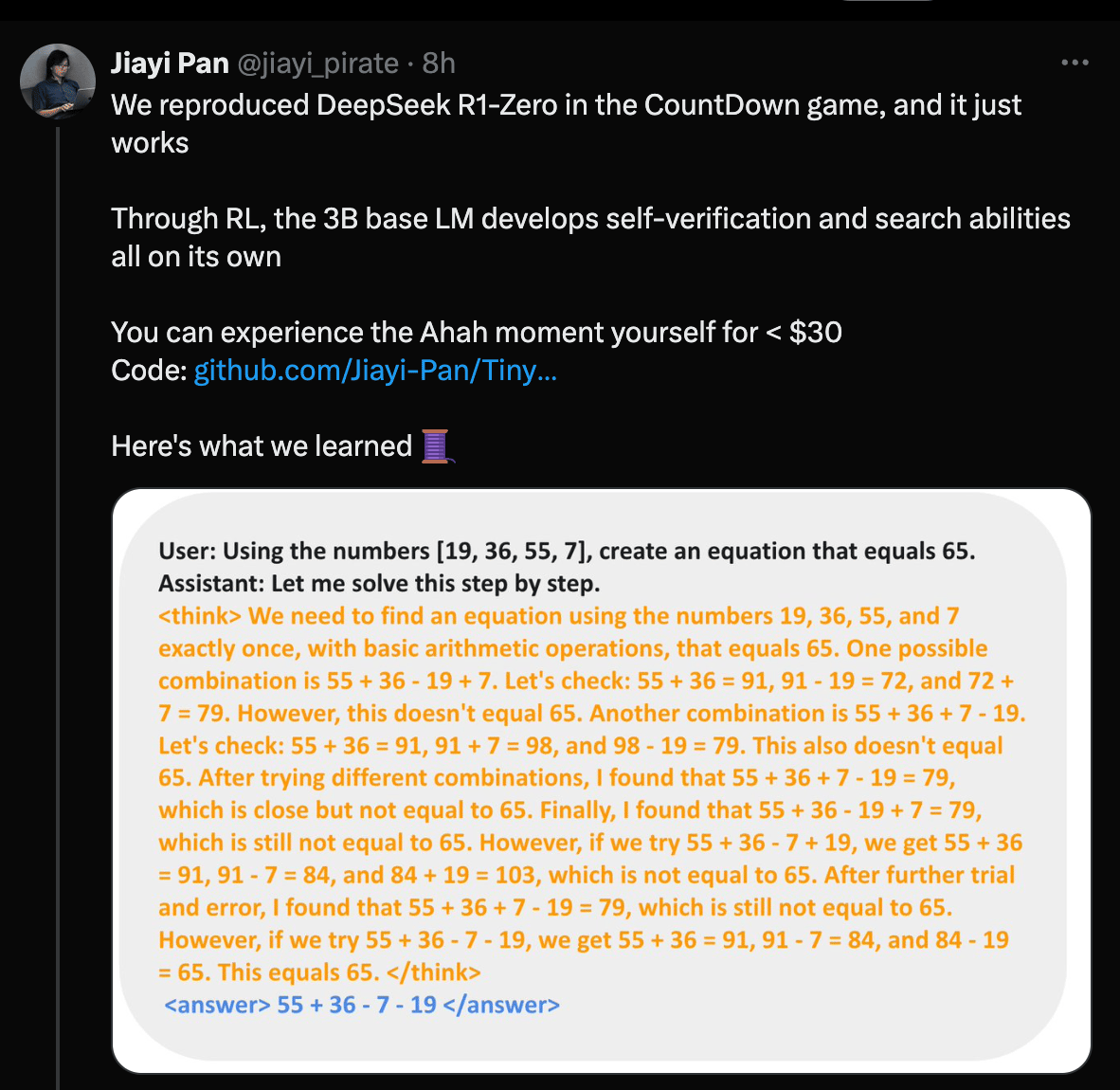
You can check out the code for this experiment here [Link].
Researchers have also been able to replicate the RL magic on math reasoning.

HuggingFace is also working on a full replication of DeepSeek-R1, open sourcing everything including training data. You can check out their GitHub repo here [Link].
From initial tests, it seems the findings are legit, which makes the next points seem quite silly.
There are a number of people who believe that DeepSeek is a CCP agent company that is designed undermine the US and capitalism.
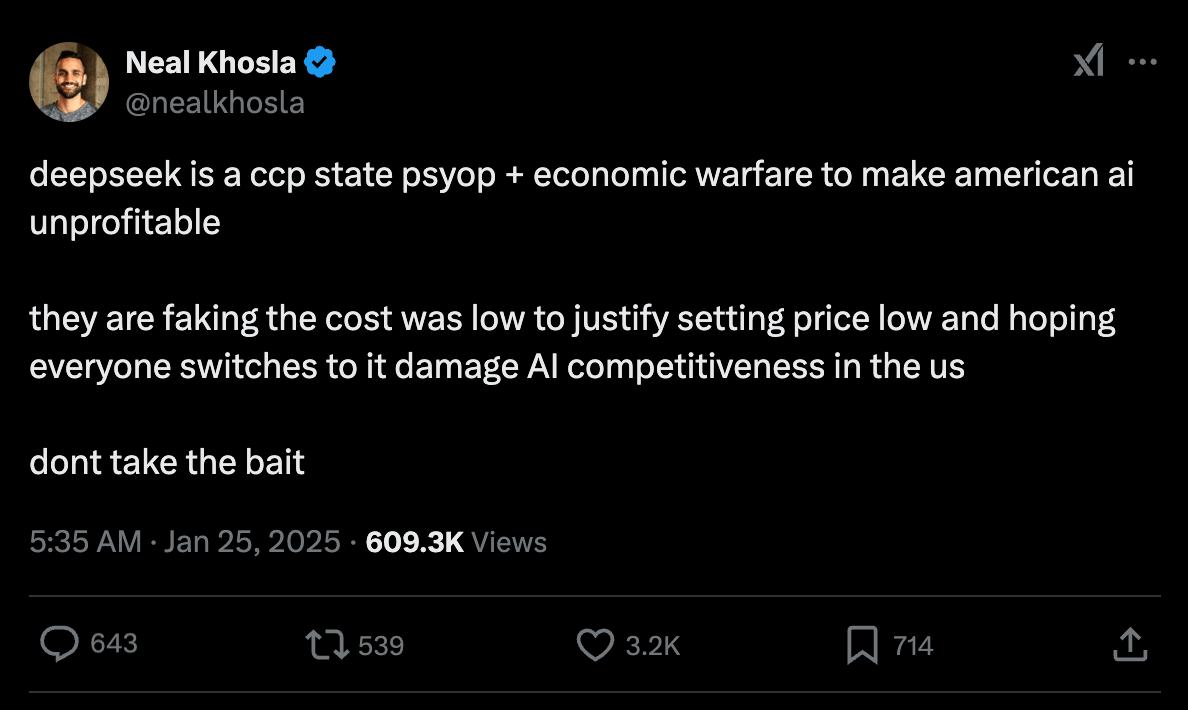
Personally, I think this is nonsense. DeepSeek has released 16(!) highly technical papers over the last two years since they got into model building retraining Llama models.
People who doubt the efficacy of their research can simply go and read the reports.
They have lots of details on how they managed to use a small amount of GPUs for their training.
Also, just as an observation - almost every person I’ve seen (on twitter) say DeepSeek is a psyop, has been a VC.
Is DeepSeek a CCP psyop? |
One thing is for certain, whether it is or it isn’t, it is a net good for humanity.
There is no argument against this.
Democratising AI might become one of the most important missions in the coming decades.
It is hard to overstate how important open sourcing this model really is.
This is particularly important given the direction the US is going in.
The Stargate project
Now that Trump is President and big tech is essentially running the gov (don’t come for me pls), the US government has announced the Stargate Project.
They’ve binned Biden’s AI Executive Order and announced a plan to invest $500 Billion over the next four years into AI infrastructure like data centres, with the intention to deploy $100 Billion immediately.
$500 Billion.
A ridiculous number.
OpenAI is leading the operational side of things.
Softbank is leading the financial oversight, with Masayoshi Son heading it himself. Other partners include Oracle and MGX, an Abu Dhabi based investment fund.
Tech partners include Microsoft, NVIDIA and Arm.
The first data centre is already being built in Texas.
How much money is the US Gov putting behind this?
None. The US is not paying anything.
But, the single most important question - who is benefitting from Stargate?
Meaning, is OpenAI the only beneficiary of the Stargate Project?
The answer to this, quite unbelievably, is yes.
OpenAI is the sole customer of Stargate.
Doesn’t this mean that OpenAI effectively raised half a trillion dollars?
… Kind of?
At the moment, Stargate has yet to actually secure the financing it needs [Link].
Anyway, the boys have been throwing all kinds of marketing words around like how AI is going to develop mRNA vaccines and cure all diseases and… mass surveillance?

Elon doesn’t think Stargate has the money either.
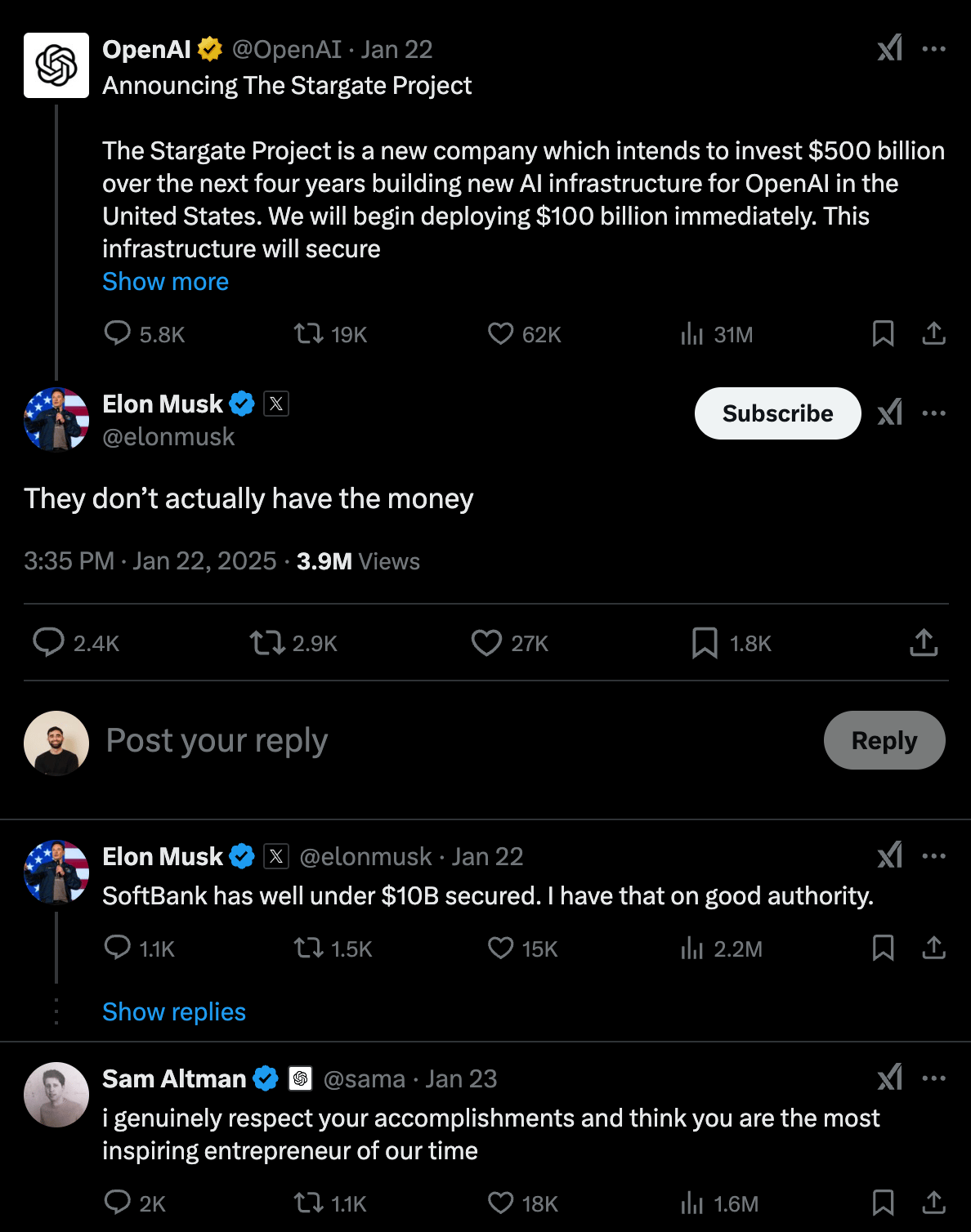
I also doubt that $500B figure. Not that they can’t raise it (which is also doubtful), but spending it. It’s a lot of money. I guess we’ll see.
Much of the arguments made by US AI labs is that we need these kinds of investments to ensure the US leads the AI arms race.
But, as DeepSeek has shown, state of the art AI models can be made without billions.
So, what’s the play here?
I mean, we have two completely different fundamental approaches.
The US is splurging billions and marketing it as AGI and ASI.
China is building world leading models at a fraction of the cost.
If China is doing the same thing as the US at a fraction of the cost, what does this mean for the US?
OpenAI is already changing the default model on ChatGPT from 4o-mini to o3-mini.
I’m not saying scaling laws are dead, meaning that more compute = better models.
But, how is OpenAI planning to make money (at scale) if a Chinese AI model is doing what it’s top models can do?
How are they going to get the ROI on half a trillion?
Where is the moat?
DeepSeek founder doesn’t think there is one.

Is DeepSeek not exposing the whole sector as a giant bubble full of capital misallocation and over-investment?
The western model was to maximise on chips, buying 100K+.
These guys used 2k chips to train a very strong base model.
I don’t doubt they have many more chips (20k+), but still nothing in comparison to what US companies are doing.
I think I’m starting accept that I will never understand the stock market.
God bless those who do, if they even exist.
Also, it seems like people are freaking out because there’s no longer a “secret sauce” to building state of the art models. DeepSeek has kind of “lifted the veil” on how to build world leading AI models.
Want to learn AI?
Feed the DeepSeek technical papers to DeepSeek and ask it to explain how the models got built.
Congratulations, you now know more about AI than most people on the planet.
What’s next?
Here are a few resources to read:
The best part for us is that there are a lot more new models and news coming in the next few weeks.
I’m most excited about what Anthropic will release considering Sonnet 3.5 is the best base model on the planet. Apparently, they already have a hidden juggernaut behind the scenes [Link].
There are two other Chinese models and a tonne of new stuff from Google to talk about as well.
I’ll see you guys next week 🙂.
I particularly enjoyed writing this one, and could’ve written a lot more, but, it’s already way too long.
Please consider supporting this newsletter. It helps me write more :).
How was this edition? |
As always, Thanks for Reading ❤️
Written by a human named Nofil
Reply